Сегментация в цветовом пространстве RGB. Muthukrishnan R, Radha M
Сегментация изображений с U-Net на практике
Введение
В этом блог посте мы посмотрим как Unet работает, как реализовать его, и какие данные нужны для его обучения. Для этого мы будем рассматривать:
- как источник для вдохновения.
- Pytorch как инструмент для реализации нашей задумки.
- Kaggle соревнования как место где мы можем опробовать наши гипотезы на реальных данных.
Мы не будем следовать на 100% за статьей, но мы постараемся реализовать ее суть, адаптировать под наши нужды.
Презентация проблемы
В этой задаче нам дано изображение машины и его бинарная маска(локализующая положение машины на изображении). Мы хотим создать модель, которая будет будет способна отделять изображение машины от фона с попиксельной точностью более 99%.
Для понимания того что мы хотим, gif изображение ниже:
Изображение слева - это исходное изображение, справа - маска, которая будет применяться на изображение. Мы будем использовать Unet нейронную сеть, которая будет учиться автоматически создавать маску.
- Подавая в нейронную сеть изображения автомобилей.
- Используя функцию потерь, сравнивая вывод нейронной сети с соответствующими масками и возвращающую ошибку для сети, чтобы узнать в каких местах сеть ошибается.
Структура кода
Код был максимально упрощен для понимания как это работает. Основной код находится в этом файле main.py , разберем его построчно.
Код
Мы будем итеративно проходить через код в main.py и через статью. Не волнуйтесь о деталях, спрятанных в других файлах проекта: нужные мы продемонстрируем по мере необходимости.
Давайте
начнем
с
начала
:
def
main
():
# Hyperparameters
input_img_resize =
(572
, 572
) # The resize size of the input images of the neural net
output_img_resize =
(388
, 388
) # The resize size of the output images of the neural net
batch_size =
3
epochs =
50
threshold =
0.
5
validation_size =
0.
2
sample_size =
None
# -- Optional parameters
threads =
cpu_count()
use_cuda =
torch.cuda.is_available()
script_dir =
os.path.dirname(os.path.abspath(__file__
))
# Training callbacks
tb_viz_cb =
TensorboardVisualizerCallback(os.path.join(script_dir,"../logs/tb_viz"
))
tb_logs_cb =
TensorboardLoggerCallback(os.path.join(script_dir,"../logs/tb_logs"
))
model_saver_cb =
ModelSaverCallback(os.path.join(script_dir,"../output/models/model_"
+
helpers.get_model_timestamp()), verbose=
True
)
В первом разделе вы определяете свои гиперпараметры, их можете настроить по своему усмотрению, например в зависимости от вашей памяти GPU. Optimal parametes определяют некоторые полезные параметры и callbacks . TensorboardVisualizerCallback - это класс, который будет сохранять предсказания в tensorboard в каждую эпоху тренировочного процесса, TensorboardLoggerCallback сохранит значения функций потерь и попиксельную «точность» в tensorboard . И наконец ModelSaverCallback сохранит вашу модель после завершения обучения.
# Download the datasets
ds_fetcher =
DatasetFetcher
()
ds_fetcher.
download_dataset()
Этот раздел автоматически загружает и извлекает набор данных из Kaggle. Обратите внимание, что для успешной работы этого участка кода вам необходимо иметь учетную запись Kaggle с логином и паролем, которые должны быть помещены в переменные окружения KAGGLE_USER и KAGGLE_PASSWD перед запуском скрипта. Также требуется принять правила конкурса, перед загрузкой данных. Это можно сделать на вкладке загрузки данных конкурса
# Get the path to the files for the neural net X_train, y_train, X_valid, y_valid = ds_fetcher.get_train_files(sample_size= sample_size, validation_size= validation_size) full_x_test = ds_fetcher.get_test_files(sample_size) # Testing callbacks pred_saver_cb = PredictionsSaverCallback(os.path.join (script_dir,"../output/submit.csv.gz" ), origin_img_size, threshold)
Эта строка определяет callback функцию для теста (или предсказания). Она будет сохранять предсказания в файле gzip каждый раз, когда будет произведена новая партия предсказания. Таким образом, предсказания не будут сохранятся в памяти, так как они очень большие по размеру.
После окончания процесса предсказания вы можете отправить полученный файл submit.csv.gz из выходной папки в Kaggle.
# -- Define our neural net architecture
# The original paper has 1
input channel, in
our case
we have 3
(RGB
)
net =
unet_origin.
UNetOriginal
((3
, *img_resize))
classifier =
nn.
classifier.
CarvanaClassifier
(net, epochs)
optimizer =
optim.
SGD
(net.
parameters()
, lr=
0.01
, momentum=
0.99
)
train_ds =
TrainImageDataset
(X_train
, y_train, input_img_resize, output_img_resize, X_transform
=
aug.
augment_img)
train_loader =
DataLoader
(train_ds, batch_size,
sampler=
RandomSampler
(train_ds),
num_workers=
threads,
pin_memory=
use_cuda)
valid_ds =
TrainImageDataset
(X_valid
, y_valid, input_img_resize, output_img_resize, threshold=
threshold)
valid_loader =
DataLoader
(valid_ds, batch_size,
sampler=
SequentialSampler
(valid_ds),
num_workers=
threads,
pin_memory=
use_cuda)
print
("Training on {} samples and validating on {} samples "
.
format(len(train_loader.
dataset), len(valid_loader.
dataset)))
# Train the classifier
classifier.
train(train_loader, valid_loader, epochs, callbacks=
)
Наконец, мы делаем то же самое, что и выше, но для прогона предсказания. Мы вызываем наш pred_saver_cb.close_saver() , чтобы очистить и закрыть файл, который содержит предсказания.
Реализация архитектуры нейронной сети
Статья Unet представляет подход для сегментации медицинских изображений. Однако оказывается этот подход также можно использовать и для других задач сегментации. В том числе и для той, над которой мы сейчас будем работать.
Перед тем, как идти вперед, вы должны прочитать статью полностью хотя бы один раз. Не волнуйтесь, если вы не получили полного понимания математического аппарата, вы можете пропустить этот раздел, также как главу «Эксперименты». Наша цель заключается в получении общей картины.
Задача оригинальной статьи отличается от нашей, нам нужно будет адаптировать некоторые части соответственно нашим потребностям.
В то время, когда была написана работа, были пропущены 2 вещи, которые сейчас необходимы для ускорения сходимости нейронной сети:
- BatchNorm.
- Мощные GPU.
Первое был изобретено всего за 3 месяца до Unet , и вероятно слишком рано, чтобы авторы Unet добавили его в свою статью.
На сегодняшний день BatchNorm используется практически везде. Вы можете избавиться от него в коде, если хотите оценить статью на 100%, но вы можете не дожить до момента, когда сеть сойдется.
Что касается графических процессоров, в статье говорится:
To minimize the overhead and make maximum use of the GPU memory, we favor large input tiles over a large batch size and hence reduce the batch to a single image
Они использовали GPU с 6 ГБ RAM, но в настоящее время у GPU больше памяти, для размещения изображений в одном batch’e. Текущий batch равный трем, работает для графического процессора в GPU с 8 гб RAM. Если у вас нет такой видеокарты, попробуйте уменьшить batch до 2 или 1.
Что касается методов augmentations (то есть искажения исходного изображения по какому либо паттерну), рассматриваемых в статье, мы будем использовать отличные от описываемых в статье, поскольку наши изображения сильно отличаются от биомедицинских изображений.
Теперь давайте начнем с самого начала, проектируя архитектуру нейронной сети:
Вот как выглядит Unet. Вы можете найти эквивалентную реализацию Pytorch в модуле nn.unet_origin.py.
Все классы в этом файле имеют как минимум 2 метода:
- __init__() где мы будем инициализировать наши уровни нейронной сети;
- forward() который является методом, называемым, когда нейронная сеть получает вход.
Давайте рассмотрим детали реализации:
- ConvBnRelu - это блок, содержащий операции Conv2D, BatchNorm и Relu. Вместо того, чтобы набирать их 3 для каждого стека кодировщика (группа операций вниз) и стеков декодера (группа операций вверх), мы группируем их в этот объект и повторно используем его по мере необходимости.
- StackEncoder инкапсулирует весь «стек» операций вниз, включая операции ConvBnRelu и MaxPool , как показано ниже:
Мы отслеживаем вывод последней операции ConvBnRelu в x_trace и возвращаем ее, потому что мы будем конкатенировать этот вывод с помощью стеков декодера.
- StackDecoder - это то же самое, что и StackEncoder, но для операций декодирования, окруженных ниже красным:
Обратите внимание, что он учитывает операцию обрезки / конкатенации (окруженную оранжевым), передавая в down_tensor, который является не чем иным, как тензором x_trace, возвращаемым нашим StackEncoder .
- UNetOriginal - это место, где происходит волшебство. Это наша нейронная сеть, которая будет собирать все маленькие кирпичики, представленные выше. Методы init и forward действительно сложны, они добавляют кучу StackEncoder , центральной части и под конец несколько StackDecoder . Затем мы получаем вывод StackDecoder , добавляем к нему свертку 1x1 в соответствии со статьей, но вместо того, чтобы определять два фильтра в качестве вывода, мы определяем только 1, который фактически будет нашим прогнозом маски в оттенках серого. Далее мы «сжимаем» наш вывод, чтобы удалить размер канала (всего 1, поэтому нам не нужно его хранить).
Если вы хотите понять больше деталей каждого блока, поместите контрольную точку отладки в метод forward каждого класса, чтобы подробно просмотреть объекты. Вы также можете распечатать форму ваших тензоров вывода между слоями, выполнив печать (x.size() ).
Тренировка нейронной сети
- Функция потерь
Теперь к реальному миру. Согласно статье:
The energy function is computed by a pixel-wise soft-max over the final feature map combined with the cross-entropy loss function.
Дело в том, что в нашем случае мы хотим использовать dice coefficient как функцию потерь вместо того, что они называют «энергетической функцией», так как это показатель, используемый в соревновании Kaggle , который определяется:
X является нашим предсказанием и Y - правильно размеченной маской на текущем объекте. |X| означает мощность множества X (количество элементов в этом множестве) и ∩ для пересечения между X и Y .
Код для dice coefficient можно найти в nn.losses.SoftDiceLoss .
class SoftDiceLoss (nn.Module): def __init__(self, weight= None, size_average= True): super (SoftDiceLoss, self).__init__() def forward(self, logits, targets): smooth = 1 num = targets.size (0 ) probs = F.sigmoid(logits) m1 = probs.view(num, - 1 ) m2 = targets.view(num, - 1 ) intersection = (m1 * m2) score = 2 . * (intersection.sum(1 ) + smooth) / (m1.sum(1 ) + m2.sum(1 ) + smooth) score = 1 - score.sum() / num return scoreПричина, по которой пересечение реализуется как умножение, и мощность в виде sum() по axis 1 (сумма из трех каналов) заключается в том, что предсказания и цель являются one-hot encoded векторами.
Например, предположим, что предсказание на пикселе (0, 0) равно 0,567, а цель равна 1, получаем 0,567 * 1 = 0,567. Если цель равна 0, мы получаем 0 в этой позиции пикселя.
Мы также использовали плавный коэффициент 1 для обратного распространения. Если предсказание является жестким порогом, равным 0 и 1, трудно обратно распространять dice loss .
Затем мы сравним dice loss с кросс-энтропией, чтобы получить нашу функцию полной потери, которую вы можете найти в методе _criterion из nn.Classifier.CarvanaClassifier . Согласно оригинальной статье они также используют weight map в функции потери кросс-энтропии, чтобы придать некоторым пикселям большее ошибки во время тренировки. В нашем случае нам не нужна такая вещь, поэтому мы просто используем кросс-энтропию без какого-либо weight map.
2. Оптимизатор
Поскольку мы имеем дело не с биомедицинскими изображениями, мы будем использовать наши собственные augmentations . Код можно найти в img.augmentation.augment_img . Там мы выполняем случайное смещение, поворот, переворот и масштабирование.
Тренировка нейронной сети
Теперь можно начать обучение. По мере прохождения каждой эпохи вы сможете визуализировать, предсказания вашей модели на валидационном наборе.
Для этого вам нужно запустить Tensorboard в папке logs с помощью команды:
Tensorboard --logdir=./logs
Пример того, что вы сможете увидеть в Tensorboard после эпохи 1:
Отправить свою хорошую работу в базу знаний просто. Используйте форму, расположенную ниже
Студенты, аспиранты, молодые ученые, использующие базу знаний в своей учебе и работе, будут вам очень благодарны.
Размещено на http://www.allbest.ru/
Министерство образования и науки РФ
Рязанский государственный радиотехнический университет
Кафедра ИИБМТ
Курсовая работа
Методы обработки изображений. Сегментация
Выполнил ст. гр. 432М:
Алёшин С.И.
Проверил доц. каф. ИИБМТ:
Каплан М.Б.
Рязань 2014
Введение
1. Представление изображений
3. Форматы изображений
4. Типы изображений
5.1 Изменение контраста
5.2 Сглаживание шумов
5.3 Подчеркивание границ
5.4 Медианная фильтрация
5.5 Сегментация изображений
5.5.3 Выделение контуров
5.5.7 Методы разреза графа
6. Описание функций
7. Тестирование алгоритма
Заключение
Приложение
Введение
Ещё в середине XX века обработка изображений была по большей части аналоговой и выполнялась оптическими устройствами. Подобные оптические методы до сих пор важны, в таких областях как, например, голография. Тем не менее, с резким ростом производительности компьютеров, эти методы всё в большей мере вытеснялись методами цифровой обработки изображений. Методы цифровой обработки изображений обычно являются более точными, надёжными, гибкими и простыми в реализации, нежели аналоговые методы. В цифровой обработке изображений широко применяется специализированное оборудование, такое как процессоры с конвейерной обработкой инструкций и многопроцессорные системы. В особенной мере это касается систем обработки видео. Обработка изображений выполняется также с помощью программных средств компьютерной математики, например, MATLAB, Mathcad, Maple, Mathematica и др. Для этого в них используются как базовые средства, так и пакеты расширения Image Processing.
Интерес к методам цифровой обработки изображений произрастает из двух основных областей ее применения, которыми являются повышение качества изображений для улучшения его визуального восприятия человеком и обработка изображений для их хранения, передачи и представления в автономных системах машинного зрения.
Одним из самых сложных методов цифрой обработки изображения является сегментация изображений. Сегментация - это процесс разделения цифрового изображения на несколько сегментов, которые отличаются друг от друга элементарными признаками, такими как яркость, цвет, текстура, форма. Цель сегментации заключается в упрощении и изменении представления изображения, чтобы его было проще и легче анализировать. Неправильное выделение сегментов на изображении в конечном счете может отразиться на качестве распознавания и даже сделать его невозможным. Поэтому задача сегментации является чрезвычайно важной и очень актуальной.
Существуют многие методы сегментации изображений. Конечный результат зачастую определяется точностью сегментации, поэтому при выборе того или иного метода сегментации нужно уделять большое внимание надежности алгоритма. Однако, единого, общепризнанного подхода, который бы лежал в основе большинства алгоритмов, нет. Нет также и единого алгоритма, который позволял бы проводить приемлемую сегментацию для любого изображения. В этом и заключается одна из сложностей сегментации, и это является причиной большого числа различных подходов при решении данных задач обработки изображений.
Несмотря на актуальность этой предметной области, было написано сравнительно мало книг, в которых рассматривались бы одновременно и теоретические основы, и программные аспекты решения основных задач сегментации изображений.
В данной работе изложены основные методы цифровой обработки изображений. В особой мере уделено внимание методам сегментации изображений. Реализована программа для одного из методов сегментации с помощью пакета прикладных программ MatLAB.
1. Представление изображений
Принципиальными вопросами в теории обработки изображений являются вопросы: формирования, ввода, представления в компьютере и визуализации. Форму поверхности можно описать в виде функции расстояния F(x, y) от поверхности до точки изображения с координатами x и y. Учитывая, что яркость точки на изображении зависит исключительно от яркости соответствующего участка поверхности, то можно считать, что визуальная информация с определенной степенью точности отражает состояние яркости или прозрачности каждой точки. Тогда под изображением понимается ограниченная функция двух пространственных переменных f(x, y), заданная на ограниченной прямоугольной плоскости Oxy и имеющая определенное множество своих значений. Например, черно-белая фотография может быть представлена как f(x, y)?0, где 0?x?a, 0?y?b и f(x, y) - яркость (иногда называемая оптической плотностью или степенью белизны) изображения в точке (x, y); a - ширина кадра, b - высота кадра.
В связи с тем, что цифровая память компьютера способна хранить только массивы данных, сначала изображение преобразуется в некоторую числовую форму (матрицу). Ввод изображений в память компьютера осуществляется с помощью видео датчиков. Видео датчик переводит оптическое распределение яркости изображения в электрические сигналы и далее в цифровые коды. Поскольку изображение является функцией двух пространственных переменных x и y, а электрический сигнал - функцией одной переменной t (времени), то для преобразования используется развертка. Например, при использовании телевизионной камеры изображение считывается по строкам, при этом в пределах каждой строки зависимость яркости от пространственной координаты x преобразуется в пропорциональную зависимость амплитуды электрического сигнала от времени t. Переход от конца предыдущей строки к началу следующей происходит практически мгновенно.
Ввод изображений в компьютер неизбежно связан с дискретизацией изображений по пространственным координатам x и y и квантованием значения яркости в каждой дискретной точке. Дискретизация достигается с помощью координатной сетки, образованной линиями, параллельными осям x и y декартовой системы координат. В каждом узле такой решетки делается отсчет яркости или прозрачности носителя зрительно воспринимаемой информации, которая затем квантуется и представляется в памяти компьютера. Элемент изображения, полученной в процессе дискретизации изображения, называется пиксел. Для качественного представления полутонового изображения достаточно 28 = 256 уровней квантования, т.е. 1 пиксел изображения кодируется 1 байтом информации.
Основными характеристиками изображений являются:
1. Размер изображения;
2. Глубина цвета;
3. Разрешение.
2. Кодирование цветных изображений
Цвет - это феномен, который является результатом взаимодействия света, объекта и прибора (наблюдателя).
Экспериментально установлено, что любой цвет можно представить в виде суммы определенных количеств трех линейно независимых цветов.
Три линейно независимых цвета называют первичными цветами.
Они определяют цветовую координатную систему (ЦКС) или цветовую схему, т.е. набор первичных цветов для получения остальных цветов.
Цветовые схемы подразделяются на две разновидности: цветовые схемы от излучаемого света и от отраженного света.
Система RGB.
Ее первичными цветами являются красный (Red) с длиной волны 700 нм, зеленый (Green) с длиной волны 546,1 нм и синий (Blue) с длиной волны 435,8 нм. Система RGB является аддитивной.
При этом тот или иной цвет получается сложением первичных цветов.
Система CMYK.
Данная система используется для формирования цветов окрашенных несветящихся объектов, которые поглощают часть спектра освещенного белого света и отражают остальное излучение.
Система CMYK является основой для цветовой печати.
Она основана на субтрактивной модели CMY (Cyan - голубой, Magenta - пурпурный, Yellow - желтый) - модели вычитания цветов. Основных цветов здесь по-прежнему три.
Для улучшения качества полиграфического изображения в систему добавлен черный цвет.
Система HSB.
Эта система основана на использовании тона (Hue) или оттенка, насыщенности (Saturation) и освещенности (Lightness). Тон характеризует конкретный оттенок цвета, насыщенность - его относительную интенсивность, яркость цвета - величину черного оттенка для получения более темного изображения.
Разновидностью этой системы является схема HSL.
3. Форматы изображений
В настоящее время используется большое количество различных форматов графических файлов. Наиболее широко распространенными из них являются форматы TIFF, GIF, JPEG, PNG и BMP.
Формат TIFF (Tagget Image Format) является одним из наиболее надежных и универсальных форматов для хранения сканированных цветных изображений с высоким качеством. В нем может быть использовано сжатие по алгоритму LZW, т.е. он относится к форматам хранения изображений без потерь.
Формат GIF (Graphics Interchange Format) имеет цветовую палитру в 256 цветов и использует для сжатия алгоритм без потерь LZW. Если исходное количество цветов больше 256, то часть цветовой информации будет утрачена.
Формат JPEG (Join Photographers Expert Group) основан на одноименном алгоритме для сжатия изображений. Он относится к алгоритмам сжатия с потерями и предназначен для хранения полноцветных изображений с высоким коэффициентом сжатия. При использовании формата возможно управление параметром качества от 0 (максимальное сжатие) до 100 (максимальное качество). Коэффициент сжатия в зависимости от качества от 10 до 1000. Этот формат чаще других применяют для хранения полноцветных фотографических изображений, которые не предназначены для дальнейшей обработки.
Формат PNG - растровый формат хранения графической информации, использующий сжатие без потерь по алгоритму Deflate. Формат PNG спроектирован для замены устаревшего и более простого формата GIF, а также, в некоторой степени, для замены значительно более сложного формата TIFF. Формат PNG позиционируется прежде всего для использования в сети Интернет и редактирования графики. Он имеет следующие основные преимущества перед GIF: практически неограниченное количество цветов в изображении; опциональная поддержка альфа-канала; возможность гамма-коррекции; двумерная чересстрочная развёртка.
Формат BMP (BitMaP) относится к собственным растровым форматам операционной системы Windows. Он пригоден для хранения изображений как в индексированном виде с палитрой до 256 цветов, так и в виде полноцветных RGB - изображений с глубиной цвета 24 бита. Возможно применение алгоритма сжатия RLE.
4. Типы изображений
4.1 Двухуровневое (или монохроматическое) изображение
В этом случае все пикселы могут иметь только два значения, которые обычно называют черным (двоичная единица, или основной цвет) и белым (двоичный нуль или цвет фона).
Каждый пиксел такого изображения представлен одним битом, поэтому это самый простой тип изображения.
1. Полутоновое изображение. Такое изображение со шкалой из 2n уровней составлено из n-битовых слоев.
2. Цветное изображение. Такое изображение описывается в одном из форматов, представленных выше.
3. Изображение с непрерывным тоном. Этот тип изображений может иметь много похожих цветов (или полутонов). Когда соседние пикселы отличаются всего на единицу, глазу практически невозможно различить их цвета. В результате такие изображения могут содержать области, в которых цвет кажется глазу непрерывно меняющимся. В этом случае пиксел представляется или большим числом (в полутоновом случае) или тремя компонентами (в случае цветного образа). Изображения с непрерывным тоном являются природными или естественными (в отличие от рукотворных, искусственных); обычно они получаются при съемке на цифровую фотокамеру или при сканировании фотографий или рисунков.
4. Дискретно-тоновое изображение (оно еще называется синтетическим). Обычно, это изображение получается искусственным путем. В нем может быть всего несколько цветов или много цветов, но в нем нет шумов и пятен естественного изображения. Примерами таких изображений могут служить фотографии искусственных объектов, машин или механизмов, страницы текста, карты, рисунки или изображения на дисплее компьютера. (Не каждое искусственное изображение будет обязательно дискретно-тоновым. Сгенерированное компьютером изображение, которое должно выглядеть натуральным, будет иметь непрерывные тона, несмотря на свое искусственное происхождение.) Искусственные объекты, тексты, нарисованные линии имеют форму, хорошо определяемые границы. Они сильно контрастируют на фоне остальной части изображения (фона). Прилегающие пикселы дискретно-тонового образа часто бывают одиночными или сильно меняют свои значения. Такие изображения плохо сжимаются методами с потерей данных, поскольку искажение всего нескольких пикселов буквы делает ее неразборчивой, преобразует привычное начертание в совершенно неразличимое. Дискретно-тоновые изображения, обычно, несут в себе большую избыточность. Многие ее фрагменты повторяются много раз в разных местах изображения.
5. Изображения, подобные мультфильмам. Это цветные изображения, в которых присутствуют большие области одного цвета. При этом соприкасающиеся области могут весьма различаться по своему цвету.
5. Методы обработки изображений
Предварительный анализ изображений позволяет сделать вывод о том, что:
Во-первых, большинство изображений, в процессе их формирования (фотографирования сканирования и т.д.), подвергаются влиянию ряда негативных факторов (вибрация фотокамеры, неравномерность движения сканирующего элемента и т.д.), приводящих к смазанности, появлению малоконтрастных и зашумленных участков и т.д.
Во-вторых, подавляющее большинство методов основано на выделении объектов на изображении и дальнейшем их анализе.
Таким образом, прежде чем подвергнуться анализу, изображение должно пройти этап препарирования, который состоит в выполнении операций улучшения визуального качества (повышение контраста, устранение размытости, подчеркивание границ, фильтрация) и операций формирования графического препарата (сегментация, выделение контуров) изображения.
5.1 Изменение контраста
Слабый контраст обычно вызван малым динамическим диапазоном изменения яркости, либо сильной нелинейностью в передаче уровней яркости. Простейшим методом контрастирования является функциональное отображение градации яркости fij в gij, то есть gij = R(fij). На практике очень часто используют линейные функциональные отображения. Если в результате неравномерности освещения при фотографировании или изготовлении фотографий, возникает ситуация, когда различные участки изображения обладают разным контрастом. В таком случае для изменения контраста используют адаптивные алгоритмы контрастирования. Примером может служить алгоритм локального усиления контраста. Экспериментальные исследования подтвердили высокую эффективность работы алгоритма в том случае, если на снимке присутствуют области с явно завышенным или заниженным контрастами.
Суть алгоритма состоит в том, что снимок рассматривается как набор некоторого числа локальных областей, и эти области обрабатываются с учетом их характеристик. Обработка ведется в следующей последовательности: вычисляется коэффициент усиления срезов плотности р отдельно для каждого локального участка изображения. И осуществляется обработка каждого пикселя изображения. Если р равно единице, то над локальным участком изображения никакого действия не производится (если р отлично от единицы, то осуществляется повышение контраста локальной области). Первоначально вычисляется контраст в анализируемой точке относительно ближайшей окрестности. Затем значение относительного контраста складывается с единицей, и полученное значение принимается в алгоритме как коэффициент усиления p, а далее производится вычисление по формуле:
изображение сегментация программа контраст
где - новое значение яркости, - текущая яркость обрабатываемого изображения, - необходимое максимальное значение яркости обработанного изображения.
5.2 Сглаживание шумов
Изображения на этапе оцифровки подвергаются воздействию аддитивного и импульсного шума. Аддитивный шум представляет собой некоторый случайный сигнал, который прибавляется к полезному на выходе системы, в рассматриваемом случае аддитивный шум возникает вследствие зернистости пленки. Импульсный шум, в отличие от аддитивного, характеризуется воздействием на полезный сигнал лишь в отдельных случайных точках (значение результирующего сигнала в этих точках принимает случайное значение). Импульсный шум характерен для цифровых систем передачи и хранения изображений. Таким образом, в процессе препарирования изображения возникает задача подавления шума.
Простейшим методом, сглаживающим шум, на изображении является сглаживание, т.е. замена значения яркости каждого элемента средним значением, найденным по его окрестности:
где - множество точек, принадлежащих окрестности точки (включая и саму точку); - число точек в окрестности.
Рассмотренный метод эффективно устраняет аддитивный и импульсный шум в каждом элементе изображения.
5.3 Подчеркивание границ
Методы сглаживания изображений могут устранять шум очень эффективно. Существенным недостатком алгоритмов сглаживания является смаз изображения (т.е. снижение четкости контурных элементов), при этом величина смаза пропорциональна размеру маски, используемой для сглаживания. Для однозначного анализа изображений, особенно при вычислении геометрических характеристик структурных элементов, очень важно убрать смаз с контуров объектов в изображении, то есть усилить разницу между градациями яркости контурных элементов объекта и соседних элементов фона. В этом случае при обработке изображений используются методы подчеркивания контуров.
Обычно подчеркивание границ осуществляется методом высокочастотной пространственной фильтрации. Характеристики фильтров задаются в виде маски, в которой среднее значение должно быть равно нулю.
Еще одним методом подчеркивания границ является так называемое статическое дифференцирование. В этом методе значение яркости каждого элемента делится на статистическую оценку среднеквадратического отклонения, то есть (среднеквадратическое отклонение вычисляется в некоторой окрестности элемента).
5.4 Медианная фильтрация
Медианная фильтрация относится к нелинейным методам обработки изображений и имеет следующие преимущества перед линейной фильтрацией (классической процедуры сглаживания): сохраняет резкие перепады (границы); эффективно сглаживает импульсный шум; не изменяет яркость фона.
Медианная фильтрация осуществляется путем движения некоторой апертуры (маски) вдоль дискретного изображения и замены значения центрального элемента маски медианным значением (среднее значение упорядоченной последовательности) исходных элементов внутри апертуры. В общем случае, апертура может иметь самую разнообразную форму, но на практике чаще всего применяется квадратная апертура размером
5.5 Сегментация изображений
Под сегментацией изображения понимается процесс его разбиения на составные части, имеющие содержательный смысл: объекты, их границы или другие информативные фрагменты, характерные геометрические особенности и др. В случае автоматизации методов получения изображений сегментацию необходимо рассматривать как основной начальный этап анализа, заключающийся в построении формального описания изображения, качество выполнения которого во многом определяет успех решения задачи распознавания и интерпретации объектов.
В общем случае сегментация представляет собой операцию разбиения конечного множества плоскости, на которой определена функция исходного изображения на непустых связанных подмножеств в соответствии с некоторым предикатом, определяемом на множестве и принимающий истинные значения, когда любая пара точек из каждого подмножества удовлетворяет некоторому критерию однородности (например, критерий однородности, основанный на оценке максимальной разности яркости отдельного пикселя и среднего значения яркости, вычисленного по соответствующей области).
5.5.1 Пороговые методы сегментации
Пороговая обработка является одним из основных методов сегментации изображений, благодаря интуитивно понятным свойствам. Этот метод ориентирован на обработку изображений, отдельные однородные области которых отличаются средней яркостью. Самым распространенным методом сегментации путем пороговой обработки является бинарная сегментация, то есть когда в нашем распоряжении имеется два типа однородных участков.
В этом случае изображение обрабатывается по пикселям и преобразование каждого пикселя входного изображения в выходное определяется из соотношения:
где - параметр обработки, называемый порогом, и - уровни выходной яркости. Обработка по пикселям, положение которых на изображении не играет никакой роли, называется точечной . Уровни и играют роль меток. По ним определяют, к какому типу отнести данную точку: к H0 или к H1. Или говорят, что H0 состоит из фоновых точек, а H1 из точек интереса . Как правило, уровни и соответствуют уровням белого и черного. Будем называть классы H1 (он же класс интереса) классом объекта, а класс H0 классом фона.
Естественно сегментация может быть не только бинарной и в таком случае существующих классов больше, чем два. Такой вид сегментации называется многоуровневым. Результирующее изображение не является бинарным, но оно состоит из сегментов различной яркости. Формально данную операцию можно записать следующим образом:
где - количество уровней, а - классы изображения. В таком случае для каждого из классов должен быть задан соответствующий порог, который бы отделял эти классы между собой. Бинарные изображения легче хранить и обрабатывать, чем изображения, в которых имеется много уровней яркости .
Самым сложным в пороговой обработке является сам процесс определения порога. Порог часто записывают как функцию, имеющую вид:
где - изображение, а - некоторая характеристика точки изображения, например, средняя яркость в окрестности с центром в этой точке.
Если значение порога зависит только от, то есть одинаково для всех точек изображения, то такой порог называют глобальным. Если порог зависит от пространственных координат, то такой порог называется локальным. Если зависит от характеристики, то тогда такой порог называется адаптивным. Таким образом, обработка считается глобальной, если она относится ко всему изображению в целом, а локальной, если она относится к некоторой выделенной области.
Помимо перечисленных разграничений алгоритмов существует еще множество методов. Многие из них являются просто совокупностью других, но большинство из них, так или иначе, базируются на анализе гистограммы исходного изображения, однако есть и принципиально другие подходы, которые не затрагивают анализ гистограмм в прямом виде или переходят от них к анализу некоторых других функций.
5.5.2 Методы наращивания областей
Методы этой группы основаны на использовании локальных признаков изображения. Идея метода наращивания областей состоит в анализе сначала стартовой точки, затем ее соседних точек и т.д. в соответствии с некоторым критерием однородности, и в последующем зачислении проанализированных точек в ту или иную группу (количество стартовых точек должно быть равно количеству однородных областей на изображении). В более эффективных вариантах метода в качестве отправной точки используются не отдельные пиксели, а разбиение изображения на ряд небольших областей. Затем каждая область проверяется на однородность, и если результат проверки оказывается отрицательным, то соответствующая область разбивается на более мелкие участки. Процесс продолжается до тех пор, пока все выделенные области не выдержат проверку на однородность. После этого начинается формирование однородных областей при помощи наращивания.
Пороговая сегментация и сегментация по критерию однородности на основе средней яркости часто не дает желаемых результатов. Такая сегментация обычно приводит к появлению значительного числа небольших областей, не имеющих реальных прототипов на изображении. Наиболее эффективные результаты дает сегментация по критерию однородности на основе текстуры (или текстурных признаков).
5.5.3 Выделение контуров
Не редко приходится сталкиваться с задачей нахождения периметров, кривизны, факторов формы, удельной поверхности объектов и т.д. Все перечисленные задачи так или иначе связаны с анализом контурных элементов объектов.
Методы выделения контуров (границ) на изображении можно разделить на следующие основные классы:
методы высокочастотной фильтрации;
методы пространственного дифференцирования;
методы функциональной аппроксимации.
Общим для всех этих методов является стремление рассматривать границы как область резкого перепада функции яркости изображения; отличает же их вводимая математическая модель понятия границы и алгоритм поиска граничных точек.
В соответствии с поставленными задачами к алгоритмам выделения контуров предъявляются следующие требования: выделенные контура должны быть утоньщенными, без разрывов и замкнутыми. Таким образом, процесс выделения контуров несколько усложняется в связи необходимостью применять алгоритмы утоньшения и устранения разрывов. Однако и это не всегда дает желаемого результата - в большинстве случаев контуры получаются незамкнутыми и, как следствие, непригодными для ряда процедур анализа.
Разрешить возникшую задачу можно, производя оконтуривание алгоритмом прослеживания границ методом "жука", который позволяет выделить замкнутые контура объектов. Суть алгоритма состоит в следующем: на объекте выбирается некоторая стартовая граничная точка и долее происходит последовательное прослеживание контура до тех пор, пока не будет достигнута стартовая точка. В случае прослеживания контура по часовой стрелке для достижения стартовой точки осуществляется по пиксельное движение вправо, если пиксель находится вне объекта, и влево, если - на объекте.
Выделенный таким образом контур представляет собой замкнутый цепной код, т.е. последовательность координат граничных точек объекта, что очень удобно для решения поставленных задач.
5.5.4 Методы, основанные на кластеризации
Метод K -средних - это итеративный метод, который используется, чтобы разделить изображение на K кластеров. Базовый алгоритм приведён ниже:
1. Выбрать K центров кластеров, случайно или на основании некоторой эвристики;
2. Поместить каждый пиксель изображения в кластер, центр которого ближе всего к этому пикселю;
3. Заново вычислить центры кластеров, усредняя все пиксели в кластере;
4. Повторять шаги 2 и 3 до сходимости (например, когда пиксели будут оставаться в том же кластере).
Здесь в качестве расстояния обычно берётся сумма квадратов или абсолютных значений разностей между пикселем и центром кластера. Разность обычно основана на цвете, яркости, текстуре и местоположении пикселя, или на взвешенной сумме этих факторов.
K может быть выбрано вручную, случайно или эвристически.
Этот алгоритм гарантированно сходится, но он может не привести к оптимальному решению.
Качество решения зависит от начального множества кластеров и значения K.
5.5.5 Методы с использованием гистограммы
Методы с использованием гистограммы очень эффективны, когда сравниваются с другими методами сегментации изображений, потому что они требуют только один проход по пикселям. В этом методе гистограмма вычисляется по всем пикселям изображения и её минимумы и максимумы используются, чтобы найти кластеры на изображении. Цвет или яркость могут быть использованы при сравнении.
Улучшение этого метода - рекурсивно применять его к кластерам на изображении для того, чтобы поделить их на более мелкие кластеры. Процесс повторяется со всё меньшими и меньшими кластерами до тех пор, когда перестанут появляться новые кластеры.
Один недостаток этого метода - то, что ему может быть трудно найти значительные минимумы и максимумы на изображении. В этом методе классификации изображений похожи метрика расстояний и сопоставление интегрированных регионов.
Подходы, основанные на использовании гистограмм можно также быстро адаптировать для нескольких кадров, сохраняя их преимущество в скорости за счёт одного прохода. Гистограмма может быть построена несколькими способами, когда рассматриваются несколько кадров. Тот же подход, который используется для одного кадра, может быть применён для нескольких, и после того, как результаты объединены, минимумы и максимумы, которые было сложно выделить, становятся более заметны. Гистограмма также может быть применена для каждого пикселя, где информация используется для определения наиболее частого цвета для данного положения пикселя. Этот подход использует сегментацию, основанную на движущихся объектах и неподвижном окружении, что даёт другой вид сегментации, полезный в видео трекинге.
5.5.6 Методы разрастания областей
Первым был метод разрастания областей из семян. В качестве входных данных этот метод принимает изображений и набор семян. Семена отмечают объекты, которые нужно выделить. Области постепенно разрастаются, сравнивая все незанятые соседние пиксели с областью. Разность д между яркостью пикселя и средней яркостью области используется как мера схожести. Пиксель с наименьшей такой разностью добавляется в соответствующую область. Процесс продолжается пока все пиксели не будут добавлены в один из регионов.
Метод разрастания областей из семян требует дополнительного ввода. Результат сегментации зависит от выбора семян. Шум на изображении может вызвать то, что семена плохо размещены. Метод разрастания областей без использования семян - это изменённый алгоритм, который не требует явных семян. Он начинает с одной области - пиксель, выбранный здесь незначительно влияет на конечную сегментацию. На каждой итерации он рассматривает соседние пиксели так же, как метод разрастания областей с использованием семян. Но он отличается там, что если минимальная не меньше, чем заданный порог, то он добавляется в соответствующую область. В противном случае пиксель считается сильно отличающимся от всех текущих областей и создаётся новая область, содержащая этот пиксель.
Один из вариантов этого метода основан на использовании яркости пикселей. Среднее и дисперсия области и яркость пикселя-кандидата используется для построения тестовой статистики. Если тестовая статистика достаточна мала, то пиксель добавляется к области, и среднее и дисперсия области пересчитывается. Иначе, пиксель игнорируются и используется для создания новой области.
5.5.7 Методы разреза графа
Методы разреза графа могут быть эффективно применены для сегментации изображений. В этих методах изображение представляется как взвешенный неориентированный граф. Обычно, пиксель или группа пикселей ассоциируется вершиной, а веса рёбер определяют похожесть или непохожесть соседних пикселей. Затем граф разрезается согласно критерию, созданному для получения "хороших" кластеров. Каждая часть вершин (пикселей), получаемая этими алгоритмами, считается объектом на изображении.
5.5.8 Сегментация методом водораздела
В сегментации методом водораздела изображение рассматривается как некоторая карта местности, где значения яркостей представляют собой значения высот относительно некоторого уровня. Если эту местность заполнять водой, тогда образуются бассейны. При дальнейшем заполнении водой, эти бассейны объединяются. Места объединения этих бассейнов отмечаются как линии водораздела.
В такой интерпретации рассматриваются точки трех видов:
1. локального минимума;
2. точки, находящиеся на склоне, т.е. с которых вода скатывается в один и тот же локальный минимум;
3. точки локального максимума, т.е. с которых вода скатывается более чем в один минимум.
Разделение соприкасающихся предметов на изображении является одной из важных задач обработки изображений. Часто для решения этой задачи используется так называемый метод маркерного водораздела. При преобразованиях с помощью этого метода нужно определить "водосборные бассейны" и "линии водораздела" на изображении путем обработки локальных областей в зависимости от их яркостных характеристик.
Метод маркерного водораздела является одним из наиболее эффективных методов сегментации изображений.
При реализации этого метода выполняются следующие основные процедуры:
1. Вычисляется функция сегментации. Она касается изображений, где объекты размещены в темных областях и являются трудно различимыми.
2. Вычисление маркеров переднего плана изображений. Они вычисляются на основании анализа связности пикселей каждого объекта.
3. Вычисление фоновых маркеров. Они представляют собой пиксели, которые не являются частями объектов.
4. Модификация функции сегментации на основании значений расположения маркеров фона и маркеров переднего плана.
Одним из важнейших применений сегментации по водоразделам является выделение на фоне изображения однородных по яркости объектов (в виде пятен). Области, характеризующиеся малыми вариациями яркости, имеют малые значения градиента. Поэтому на практике часто встречается ситуация, когда метод сегментации по водоразделам применяется не к самому изображению, а к его градиенту.
6. Описание функций
В данной работе представлен алгоритм сегментации изображения с помощью метода маркерного водораздела.
Основные функции, используемые при создании программы:
Функция fspecial создает двумерный фильтр указанного типа;
Функция imfilter - морфологическая операция создания изображения градиента;
Функция watershed преобразования водораздела от изображения;
Функция label2rgb преобразовывает исходное изображение в полутоновое;
Функция imregionalmax определяет все локальные максимумы изображения;
Функция imextendedmin находит "низкие" пятна на изображении, лежащие глубже некоторого заданного порогового уровня по сравнению с их ближайшим окружением;
Функция imimposemin модифицирует полутоновое изображение так, что локальные минимумы достигаются только в отмеченных положениях; другие величины пикселов повышаются для исчезновения всех прочих точек локального минимума;
Функции imreconstruct и imcomplement - реконструкция изображения с помощью морфологических операций раскрытия (закрытия.)
7. Тестирование алгоритма
При реализации данного метода были выполнены следующие процедуры:
1. Считываем изображение и преобразуем его в полутоновое (рисунок 1);
Рисунок 1. Исходное (слева) и полутоновое (справа) изображения.
2. Используем значения градиента в качестве функции сегментации (рисунок 2);
Рисунок 2. Значения градиента.
3. Проводим морфологические операции над изображением (рисунок 3);
Рисунок 3. Результат применения морфологических операций раскрытия - закрытия через реконструкцию изображения.
4. Вычисляем маркеры переднего плана и фона изображения (рисунок 4);
Рисунок 4. Маркеры переднего плана (слева) и фона (справа) изображения.
5. Строим границы водоразделов (рисунок 5);
Рисунок 5. Границы водоразделов.
6. Отображаем маркеры и границы объектов на полутоновом изображении (рисунок 6);
Рисунок 6. Маркеры и границы объектов.
7. Отображаем результат сегментации с помощью цветового изображения (слева) и использую полупрозрачный режим (справа).
Рисунок 7 Результаты сегментации.
Заключение
В данной работе разработан метод маркерного водораздела для сегментации изображения.
Непосредственное применение алгоритма сегментации по водоразделам дает избыточную сегментацию, поэтому для управления избыточной сегментацией использован подход, основанный на идее маркеров.
Маркер представляет собой связную компоненту, принадлежащую изображению. Также перед проведением сегментации по водоразделам проведена необходимая предварительная обработка изображения.
Список используемых источников
1. Гонсалес Р., Вудс Р. Цифровая обработка изображений. - М.: Техносфера, 2005. 1072 с.
2. Прэтт У. Цифровая обработка изображений. - М.: Мир, кн.1, 1982. 312с.
3. Ярославский Л.П. Введение в цифровую обработку изображений. - М: Сов. радио, 1979. 312 с.
4. Прэтт У. Цифровая обработка изображений. - М: Мир, кн. 1, 1982. 480с.
5. http://www.ict.edu.ru/lib/
6. http://matlab.exponenta.ru/imageprocess/book2/76.php
7. Визильтер Ю.В. Обработка и анализ цифровых изображений с примерами на LabVIEW и IMAQ VIsion. - М: ДМК, 2011. 464 с.
8. Гонсалес Р., Вудс Р., Эддинс С. Цифровая обработка изображений в среде MATLAB. - М: Техносфера, 2006. 616 с.
9. http://matlab.exponenta.ru/imageprocess/book2/48.php
10. Сэломон Д. Сжатие данных, изображений и звука. - М.: Техносфера, 2004. 368 с.
Приложение
Считаем изображение
rgb=imread("C:\Users\Name\Documents\MATLAB\picture1.jpeg");
Представим его в виде полутонового
I=rgb2gray(rgb);figure,imshow(I);
Вычисляем значение градиента
hy=fspecial("sobel"); hx=hy";
Iy=imfilter(double(I), hy, "replicate");
Ix=imfilter(double(I), hx, "replicate");
gradmag=sqrt(Ix.^2+Iy.^2);
Применим метод водораздела
L=watershed(gradmag);Lrgb=label2rgb(L);
Морфологические операции
se = strel("disk",15);
Ie = imerode(I, se);Iobr = imreconstruct(Ie, I);
Iobrd = imdilate(Iobr, se);
Iobrcbr = imreconstruct(imcomplement(Iobrd), imcomplement(Iobr));
Iobrcbr = imcomplement(Iobrcbr);
Вычислим локальные максимумы
fgm = imregionalmax(Iobrcbr);
Наложим маркеры на изображение
I2 = I;I2(fgm) = 255;
Удаляем отдельные изолированные пиксели
se2 = strel(ones(3,3));fgm2 = imclose(fgm, se2);fgm3 = imerode(fgm2, se2);
Удаление заданного числа пикселей
fgm4 = bwareaopen(fgm3, 20);
Наложим на исходное изображение
I3 = I;I3(fgm4) = 255;
Вычислим маркеры фона
bw = im2bw(Iobrcbr, graythresh(Iobrcbr));
Измеряем расстояние до линии водораздела
D = bwdist(bw);DL = watershed(D);bgm = DL == 0;
figure, imshow(bgm), title("bgm");
Корректируем значение градиента
gradmag2 = imimposemin(gradmag, bgm | fgm4);
L = watershed(gradmag2);
Наложим маркеры и границы объектов на иходное изображение
I4 = I;I4(imdilate(L == 0, ones(3, 3)) | bgm | fgm4) = 255;
Отображение результа с помощью цветного изображения
Lrgb = label2rgb(L, "jet", "w", "shuffle");
Наложим маркеры и границы объектов на полупрозрачное изображение
figure, imshow(I), hold on
himage = imshow(Lrgb);
set(himage, "AlphaData", 0.3);
title("Lrgb2");
Размещено на Allbest.ru
...Подобные документы
Цифровые рентгенографические системы. Методы автоматического анализа изображений в среде MatLab. Анализ рентгеновского изображения. Фильтрация, сегментация, улучшение изображений. Аппаратурные возможности предварительной нормализации изображений.
курсовая работа , добавлен 07.12.2013
Выбор методов обработки и сегментации изображений. Математические основы примененных фильтров. Гистограмма яркости изображения. Программная реализация комплексного метода обработки изображений. Тестирование разработанного программного обеспечения.
курсовая работа , добавлен 18.01.2017
Изучение и программная реализация в среде Matlab методов обработки, анализа, фильтрации, сегментации и улучшения качества рентгеновских медицинских изображений. Цифровые рентгенографические системы. Разработка статически обоснованных алгоритмов.
курсовая работа , добавлен 20.01.2016
Современные системы текстурного анализа изображений. Примеры текстурной сегментации одноканальных изображений. Использование признаков, полученных на основе гистограммы яркостей второго порядка, для классификации спектрозональных аэрофотоснимков.
реферат , добавлен 15.01.2017
Компьютерная графика и обработка изображений электронно-вычислительными машинами являются наиболее важным аспектом использования ЭВМ во всех сферах человеческой деятельности. Разработка "подсистемы линейной сегментации", описание алгоритма и логики.
дипломная работа , добавлен 23.06.2008
Задачи цифровой обработки изображений. Методы пороговой сегментации. Создание программы представления рисунка в виде матрицы и применения к нему пороговой обработки. Разработка интерфейса программы загрузки и фильтрации изображения с выбранным порогом.
курсовая работа , добавлен 12.11.2012
Описание математических методов представления и обработки графических изображений. Описание разработанного программного дополнения. Описание функций и их атрибутов. Представление и обработка графических изображений. Результаты тестирования программы.
курсовая работа , добавлен 27.01.2015
Задача пространственно-временной обработки изображений при наличии шумов и помех. Методы оптимизации при пространственно-временной обработке изображений. Структура специализированной программы, описание ее пользовательского интерфейса. Смета затрат.
дипломная работа , добавлен 10.06.2013
Обнаружение деталей и их границ изображения. Применение ранговых алгоритмов. Использование алгоритмов адаптивного квантования мод в режиме пофрагментной обработки. Обобщенная линейная фильтрация изображений. Восстановление отсутствующих участков.
курсовая работа , добавлен 17.06.2013
Обзор существующего программного обеспечения для автоматизации выделения границ на изображении. Разработка математической модели обработки изображений и выделения контуров в оттенках серого и программного обеспечения для алгоритмов обработки изображений.
Пороговая обработка, вероятно, самый простой метод сегментации, что привлекает к нему большое внимание специалистов. Метод ориентирован на обработку изображений, отдельные однородные участки которых различаются средней яркостью. Простейшим и вместе с тем часто применяемым видом сегментации является бинарная сегментация, когда имеется только два типа однородных участков. При этом преобразование каждой точки исходного изображения в выходное выполняется по правилу:
 (7.1)
(7.1)
где - единственный параметр обработки, называемый порогом. Уровни выходной яркости и , могут быть произвольными, они лишь выполняют функции меток, при помощи которых осуществляется разметка получаемой карты - отнесение ее точек к классам или соответственно. Если образуемый препарат подготавливается для визуального восприятия, то часто их значения соответствуют уровням черного и белого. Если существует более двух классов, то при пороговой обработке должно быть задано семейство порогов, отделяющих яркости различных классов друг от друга.
Центральным вопросом пороговой сегментации является определение порогов, которое должно выполняться автоматически. Применяемые в настоящее время методы автоматического определения порогов подробно описаны в обзоре . Разнообразие методов очень велико, однако в основном они базируются на анализе гистограммы исходного изображения.
Пусть , - гистограмма исходного цифрового изображения. Примем, что его диапазон яркостей заключен в пределах от 0 (уровень черного) до 255 (уровень белого). Первоначальная идея гистограммного метода определения порога основывалась на предположении о том, что распределения вероятностей для каждого класса унимодальны (содержат по одному пику), а точки границ, разделяющих участки разных классов на изображении, малочисленны. Этим предположениям должна отвечать гистограмма, которая имеет многомодальный характер. Отдельные моды соответствуют различным классам, а разделяющие их впадины - малочисленным по количеству входящих в них точек граничным областям. Пороги сегментации находятся при этом по положению впадин. Рис. 7.1 иллюстрирует сказанное выше применительно к случаю двух классов. В действительности воспользоваться такими простыми соображениями для выбора порога удается крайне редко. Дело в том, что реальные гистограммы обычно сильно изрезаны, что иллюстрирует приводимый па рис.7.2, в результат эксперимента. Это служит первым препятствием для определения точек минимума. Вторым препятствием является то, что границы между однородными участками на изображении бывают размыты, вследствие чего уровень гистограммы в тех ее частях, которые отображают точки границы, возрастает. Очевидно, это приводит к уменьшению провалов в гистограмме или даже их исчезновению.

Рис.7.1.К выбору порога бинарной сегментации
Один из эффективных путей преодоления этих трудностей состоит и определении порога на основе так называемого дискриминантного критерия. Рассмотрим этот подход применительно к двум классам, поскольку обобщение на случай большего числа классов не составляет принципиальной проблемы. Итак, считаем, что распределение ,построено для изображения, содержащего два типа участков, причем существует оптимальная граница , разделяющая их наилучшим образом в некотором смысле. Для определения оптимального порога строим дискриминантную функцию , , аргумент которой имеет смысл пробного порога. Его значение, максимизирующее функцию , является оптимальным порогом . Рассмотрим построение дискриминантной функции.
Пусть - гипотетическое значение порога, разбивающее распределение , на два класса. При этом обычно не играет большой роли, к какому из классов будут отнесены точки изображения, имеющие яркость , в силу малочисленности граничных точек, разделяющие участки разных классов. Вероятность того, что наугад взятая точка кадра принадлежит классу , равна
 (7.2)
(7.2)
Аналогично вероятность ее принадлежности к классу определяется формулой
 (7.3)
(7.3)
причем в силу нормировки распределения вероятностей имеет место равенство
Далее считаем, что участок распределения
, , ограниченный точкой
, описывает
часть изображения, принадлежащую , а участок , ![]() - принадлежащую . Это позволяет ввести
в рассмотрение два распределения и , соответствующих и , конструируя их из распределения
при
помощи выражений:
- принадлежащую . Это позволяет ввести
в рассмотрение два распределения и , соответствующих и , конструируя их из распределения
при
помощи выражений:
![]()
![]()
![]()
Здесь делением на вероятности и обеспечивается нормировка вводимых условных распределений.
Для образованных таким образом распределений вероятностей могут быть найдены моменты. Выражения для математических ожиданий и имеют вид
 (7.4)
(7.4)
где  - ненормированное
математическое ожидание для ,
- ненормированное
математическое ожидание для ,  - математическое ожидание
для всего кадра.
- математическое ожидание
для всего кадра.
Аналогично, дисперсия дня всего кадра определяется выражением
 (7.6)
(7.6)
Для построения дискриминантной функции дополнительно вводим еще один энергетический параметр , называемый межклассовой дисперсией:
Безразмерная дискриминантная функция определяется выражением
![]() (7.8)
(7.8)
Оптимальным, как говорилось выше, считается порог, отвечающим требованию
![]() (7.9)
(7.9)
Поясним смысл критерия (7.9). Знаменатель в выражении (7.8) является дисперсией всего кадра и, следовательно, от величины пробного порога , разбивающего изображение на классы, не зависит. Поэтому точка максимума выражения (7.8) совпадает с точкой максимума числителя, т.е. определяется характером зависимости межклассовой дисперсии (7.7) от порога . При его стремлении к нулю вероятность , как следует из (7.2), также стремится к нулю. Поскольку при этом все изображение относится к классу , имеет место тенденция . Следовательно, оба слагаемых в (7.7) становятся равными нулю. Это же наблюдается и при другом крайнем значении порога =255. В силу неотрицательности величин, входящих в (7.7) и (7.9), и равенства функции нулю на краях области определения, внутри этой области существует максимум, абсцисса которого и принимается за оптимальный порог. Следует отметить качественный характер этих соображений. Более детальные исследования показывают, например, что при обработке некоторых изображений дискриминантная функция имеет несколько максимумов даже при наличии на изображении только двух классов. Это, в частности, проявляется, когда суммарные площади участков, занятых классами и ,существенно различны. Поэтому задача в общем случае несколько усложняется необходимостью определить абсолютный максимум функции .
С вычислительной точки зрения для выполнения алгоритма необходимо найти для всего изображения математическое ожидание и дисперсию . Далее при каждом значении определяются вероятности и с использованием (7.2) и (7.3) (или условия нормировки), а также математические ожидания классов и при помощи соотношений (7.4), (7.5). Найденные таким образом величины дают возможность определить значение .
Объем вычислений можно сократить, если выполнить некоторые преобразования формулы (7.7) для межклассовой дисперсии. Используя формулы (7.2)...(7.5), нетрудно получить соотношение для математических ожиданий:
![]() (7.11)
(7.11)
Выражая из (7.10) величину и подставляя ее в (7.11), окончательно находим:
 (7.12)
(7.12)
В соотношение (7.12), используемое в качестве рабочего, входят лишь две величины - вероятность и ненормированное математическое ожидание , что существенно уменьшает объем вычислений при автоматическом отыскании оптимального порога.
На рис. 7.2 приведены результаты эксперимента, иллюстрирующие описанный метод автоматической бинарной сегментации. На рис.7.2, а показан аэрофотоснимок участка земной поверхности "Поле", а на рис.7.2, б – результат его бинарной сегментации, выполненной на основе автоматического определения порога при помощи дискриминантного метода. Гистограмма распределения исходного изображения показана на рис.7.2, в, а дискриминантная функция , вычисленная по полученной гистограмме - на рис. 7.2, г. Сильная изрезанность гистограммы, порождающая большое количество минимумов, исключает возможность непосредственного определения единственного информационного минимума, разделяющего классы друг от друга. Функция же является существенно более гладкой и к тому же в данном случае унимодальной, что делает определение порога весьма простой задачей. Оптимальный порог, при котором получено сегментированное изображение, =100. Результаты показывают, что описанный метод нахождения порога, являясьразвитием гистограммного подхода, обладает сильным сглаживающим действием по отношению к изрезанности самой гистограммы.
Коснемся вопроса о пороговой сегментации нестационарных изображений. Если средняя яркость изменяется внутри кадра, то пороги сегментации должны быть также изменяющимися. Часто в этих случаях прибегают к разбиению кадра на отдельные области, в пределах которых изменениями средней яркости можно пренебречь. Это позволяет применять внутри отдельных областей принципы определения порогов, пригодные для работы со стационарными изображениями. На обработанном изображении наблюдаются в этом случае области, на которые разбито исходное изображение, отчетливо видны границы между областями. Это – существенный недостаток метода.
Более трудоемка, но и более эффективна процедура, использующая скользящее окно, при которой каждое новое положение рабочей области отличается от предыдущего только на один шаг по строке или по столбцу. Находимый на каждом шаге оптимальный порог относят к центральной точке текущей области. Таким образом, при этом методе порог изменяется в каждой точке кадра, причем эти изменения имеют характер, сопоставимый с характером нестационарности самого изображения. Процедура обработки, конечно, существенно усложняется.
Компромиссной является процедура, при которой вместо скользящего окна с единичным шагом применяют "прыгающее" окно, перемещающееся на каждом этапе обработки на несколько шагов. В "пропущенных" точках кадра порог может определяться с помощью интерполяции (часто применяют простейшую линейную интерполяцию) по его найденным значениям в ближайших точках.




Рис.7.2.Пример бинарной сегментации с автоматическим определением порога
Оценивая результативность пороговой сегментации по рис. 7.2, б, следует отметить, что данный метод дает возможность получить определенное представление о характере однородных областей, образующих наблюдаемый кадр. Вместе с темочевидно его принципиальное несовершенство, вызванное одноточечным характером принимаемых решений. Поэтому в последующих разделах обратимся к статистическим методам, позволяющим учитывать при сегментации геометрические свойства областей – размеры, конфигурацию и т.п. Отметим сразу же, что соответствующие геометрические характеристики задаются при этом своими вероятностными моделями и чаще всего в неявном виде.
Cегментация означает выделение областей однородных по какому-либо критерию, например по яркости. Математическая формулировка задачи сегментации может иметь следующий вид .
Пусть
-функция
яркости анализируемого изображения;
X
– конечное
подмножество плоскости на котором
определена
 ;
; - разбиение
X
на
K
непустых
связных подмножеств
- разбиение
X
на
K
непустых
связных подмножеств
 LP
–
предикат,
определенный на множестве S
и принимающий
истинные значения тогда и только тогда,
когда любая пара точек из каждого
подмножества
LP
–
предикат,
определенный на множестве S
и принимающий
истинные значения тогда и только тогда,
когда любая пара точек из каждого
подмножества
 удовлетворяет критерию однородности.
удовлетворяет критерию однородности.
Сегментацией
изображения
 по предикату
LP
называется
разбиение
по предикату
LP
называется
разбиение

 ,
удовлетворяющее условиям:
,
удовлетворяющее условиям:
а)
 ;
;
б)
 ;
;
в)
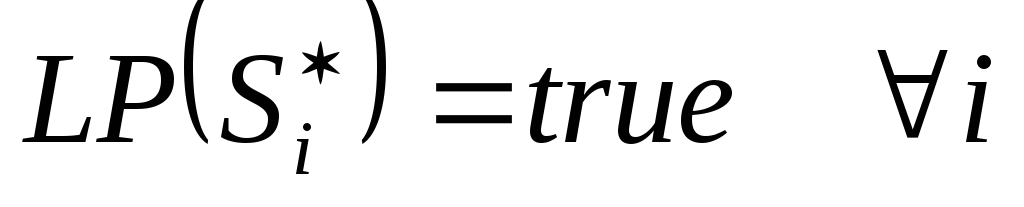 ;
;
г) смежные области.
Условия а) и б) означают, что каждая точка изображения должна быть единственным образом отнесена к некоторой области, в) определяет тип однородности получаемых областей и, наконец, г) выражает свойство “максимальности” областей разбиения.
Предикат LP называется предикатом однородности и может быть записан в виде:
 (1)
(1)
где
 -отношение
эквивалентности;
-отношение
эквивалентности;
 - произвольные точки из
- произвольные точки из
 .Таким образом,
сегментацию можно рассматривать как
оператор вида:
.Таким образом,
сегментацию можно рассматривать как
оператор вида:
где
 -функции,
определяющие исходное и сегментированное
изображение соответственно;
-функции,
определяющие исходное и сегментированное
изображение соответственно;
 -метка i-
й
области.
-метка i-
й
области.
Существуют
два общих подхода к решению задачи
сегментации
, которые
базируются на альтернативных
методологических концепциях. Первый
подход основан на идее “разрывности”
свойств
точек изображения при переходе от одной
области к другой. Этот подход сводит
задачу сегментации к задаче выделения
границ областей. Успешное решение
последней позволяет, вообще говоря,
идентифицировать и сами области, и их
границы. Второй подход реализует
стремление выделить точки изображения,
однородные по своим локальным свойствам,
и объединить их в область, которой позже
будет присвоено имя или смысловая метка.
В литературе первый подход называют
сегментацией
путем выделения границ областей
,
а второй – сегментацией
путем разметки точек области
.
Данное выше математическое определение
задачи позволяет характеризовать эти
подходы в терминах предиката однородности
LP
.
В первом
случае в качестве LP
должен
выступать предикат, принимающий истинные
значение на граничных точках областей
и ложные значения на внутренних точках.
Однако можно отметить существенное
ограничение этого подхода, состоящее
в том, что разбиение
 является
здесь двухэлементным множеством. В
практическом плане это означает, что
алгоритмы выделения границ не позволяют
идентифицировать разными метками разные
области.
является
здесь двухэлементным множеством. В
практическом плане это означает, что
алгоритмы выделения границ не позволяют
идентифицировать разными метками разные
области.
Для второго подхода предикат LP может иметь вид, определяемый соотношением (5.1). Указанные выше подходы порождают конкретные методы и алгоритмы решения задачи сегментации.
Метод сегментации на основе пороговой обработки
Пороговая обработка изображения означает преобразование его функции яркости оператором вида

где
s(x,y)
– сегментированное
изображение;
K
–
число
областей сегментации;
 - метки сегментированных областей;
- метки сегментированных областей;
 - величины порогов, упорядоченные так,
что
- величины порогов, упорядоченные так,
что
 .
.
В частном случае при K= 2 пороговая обработка предусматривает использование единственного порога T . При назначении порогов применяют, как правило, гистограмму значений фунции яркости изображения.
Алгоритм сегментации на основе пороговой обработки на псевдокоде
Вход: mtrIntens – исходная матрица полутонового изображения;
l, r – пороги по гистограмме
Выход: mtrIntensNew – матрица сегментированного изображения
for i:=0 to l-1 do
for i:=l to r do
for i:=r+1 to 255 do
LUT[i]=255;
for i:=1 to 100 do
for j:=1 to 210 do
mtrIntensNew:=LUT]
Сегментация методом управляемого водораздела
Довольно часто при анализе изображений возникает задача разделения пикселей изображений на группы по некоторым признакам. Такой процесс разбиения на группы называется сегментацией. Наиболее известными являются два вида сегментации - сегментация по яркости для бинарных изображений и сегментация по цветовым координатам для цветных изображений. Методы сегментации можно рассматривать как формализацию понятия выделяемости объекта из фона или понятий связанных с градиентом яркости. Алгоритмы сегментации характеризуются некоторыми параметрами надежности и достоверности обработки. Они зависят от того, насколько полно учитываются дополнительные характеристики распределения яркости в областях объектов или фона, количество перепадов яркости, форма объектов и др.
Существует много изображений, которые содержат исследуемый объект достаточно однородной яркости на фоне другой яркости. В качестве примера можно привести рукописный текст, ряд медицинских изображений и т.д. Если яркости точек объекта резко отличаются от яркостей точек фона, то решение задачи установления порога является несложной задачей. На практике это не так просто, поскольку исследуемое изображение подвергается воздействию шума и на нем допускается некоторый разброс значений яркости. Известно несколько аналитических подходов к пороговому ограничению по яркости. Один из методов состоит в установлении порога на таком уровне, при котором общая сумма элементов с подпороговой яркостью согласована с априорными вероятностями этих значений яркости.
Аналогичные подходы можно применить для обработки цветных и спектрозональных изображений. Существует также такой вид сегментации как контурная сегментация. Довольно часто анализ изображений включает такие операции, как получение внешнего контура изображений объектов и запись координат точек этого контура. Известно три основных подхода к представлению границ объекта: аппроксимация кривых, прослеживание контуров и связывание точек перепадов. Для полноты анализа следует отметит, что есть также текстурная сегментация и сегментация формы.
Наиболее простым видом сегментации является пороговая сегментация. Она нашла очень широкое применение в робототехнике. Это объясняется тем, что в этой сфере изображения исследуемых объектов, в своем большинстве, имеют достаточно однородную структуру и резко выделяются их фона. Но кроме этого, для достоверной обработки нужно знать, что изображение состоит из одного объекта и фона, яркости которых находятся в строго известных диапазонах и не пересекаются между собой.
Развитие технологий обработки изображений привело к возникновению новых подходов к решению задач сегментации изображений и применении их при решении многих практических задач.
В данной работе рассмотрим относительно новый подход к решению задачи сегментации изображений - метод водораздела. Коротко объясним название этого метода и в чем его суть.
Предлагается рассматривать изображение как некоторую карту местности, где значения яркостей представляют собой значения высот относительно некоторого уровня. Если эту местность заполнять водой, тогда образуются бассейны. При дальнейшем заполнении водой, эти бассейны объединяются. Места объединения этих бассейнов отмечаются как линии водораздела.
Разделение соприкасающихся предметов на изображении является одной из важных задач обработки изображений. Часто для решения этой задачи используется так называемый метод маркерного водораздела. При преобразованиях с помощью этого метода нужно определить "водосборные бассейны" и "линии водораздела" на изображении путем обработки локальных областей в зависимости от их яркостных характеристик.
Метод маркерного водораздела является одним из наиболее эффективных методов сегментации изображений. При реализации этого метода выполняются следующие основные процедуры:
Вычисляется функция сегментации. Она касается изображений, где объекты размещены в темных областях и являются трудно различимыми.
Вычисление маркеров переднего плана изображений. Они вычисляются на основании анализа связности пикселей каждого объекта.
Вычисление фоновых маркеров. Они представляют собой пиксели, которые не являются частями объектов.
Модификация функции сегментации на основании значений расположения маркеров фона и маркеров переднего плана.
Вычисления на основании модифицированной функции сегментации.
В данном примере среди функций пакета Image Processing Toolbox наиболее часто используются функции fspecial, imfilter, watershed, label2rgb, imopen, imclose, imreconstruct, imcomplement, imregionalmax, bwareaopen, graythresh и imimposemin.
- Шаг 1: Считывание цветного изображения и преобразование его в полутоновое.
- Шаг 2: Использование значения градиента в качестве функции сегментации.
- Шаг 3: Маркировка объектов переднего плана.
- Шаг 4: Вычисление маркеров фона.
- Шаг 6: Визуализация результата обработки.
Шаг 1: Считывание цветного изображения и преобразование его в полутоновое.
Считаем данные из файла pears.png rgb=imread("pears.png"); и представим их в виде полутонового изображения. I=rgb2gray(rgb); imshow(I) text(732,501,"…",... "FontSize",7,"HorizontalAlignment","right")
Шаг 2: Использование значения градиента в качестве функции сегментации.
Для вычисления значения градиента используется оператор Собеля, функция imfilter и другие вычисления. Градиент имеет большие значения на границах объектов и небольшие (в большинстве случаев) вне границ объектов.
Hy=fspecial("sobel"); hx=hy"; Iy=imfilter(double(I), hy, "replicate"); Ix=imfilter(double(I), hx, "replicate"); gradmag=sqrt(Ix.^2+Iy.^2); figure, imshow(gradmag,), title("значение градиента")

Таким образом, вычислив значения градиента, можно приступить к сегментации изображений с помощью рассматриваемого метода маркерного водораздела.
L=watershed(gradmag); Lrgb=label2rgb(L); figure, imshow(Lrgb), title("Lrgb")

Однако, без проведения еще дополнительных вычислений, такая сегментация будет поверхностной.
Шаг 3: Маркировка объектов переднего плана.
Для маркировки объектов переднего плана могут использоваться различные процедуры. В этом примере будут использованы морфологические технологии, которые называются "раскрытие через восстановление" и "закрытие через восстановление". Эти операции позволяют анализировать внутреннюю область объектов изображения с помощью функции imregionalmax.
Как было сказано выше, при проведении маркировки объектов переднего плана используются также морфологические операции. Рассмотрим некоторые из них и сравним. Сначала реализуем операцию раскрытия с использованием функции imopen.
Se=strel("disk", 20); Io=imopen(I, se); figure, imshow(Io), title("Io")

Ie=imerode(I, se); Iobr=imreconstruct(Ie, I); figure, imshow(Iobr), title("Iobr")

Последующие морфологические операции раскрытия и закрытия приведут к перемещению темных пятен и формированию маркеров. Проанализируем операции морфологического закрытия. Для этого сначала используем функцию imclose:
Ioc=imclose(Io, se); figure, imshow(Ioc), title("Ioc")

Iobrd=imdilate(Iobr, se); Iobrcbr=imreconstruct(imcomplement(Iobrd), imcomplement(Iobr)); Iobrcbr=imcomplement(Iobrcbr); figure, imshow(Iobrcbr), title("Iobrcbr")

Сравнительный визуальный анализ Iobrcbr и Ioc показывает, что представленная реконструкция на основе морфологических операций открытия и закрытия является более эффективной в сравнении с стандартными операциями открытия и закрытия. Вычислим локальные максимумы Iobrcbr и получим маркеры переднего плана.
Fgm=imregionalmax(Iobrcbr); figure, imshow(fgm), title("fgm")

Наложим маркеры переднего плана на исходное изображение.
I2=I; I2(fgm)=255; figure, imshow(I2), title("fgm, наложенное на исходное изображение")

Отметим, что при этом некоторые скрытые или закрытые объекты изображения не являются маркированными. Это свойство влияет на формирование результата и многие такие объекты изображения не будут обработаны с точки зрения сегментации. Таким образом, маркеры переднего плана отображают границы только большинства объектов. Представленные таким образом границы подвергаются дальнейшей обработке. В частности, это могут быть морфологические операции.
Se2=strel(ones(5, 5)); fgm2=imclose(fgm, se2); fgm3=imerode(fgm2, se2);
В результате проведения такой операции пропадают отдельные изолированные пиксели изображения. Также можно использовать функцию bwareaopen, которая позволяет удалять заданное число пикселей.
Fgm4=bwareaopen(fgm3, 20); I3=I; I3(fgm4)=255; figure, imshow(I3) title("fgm4, наложенное на исходное изображение")

Шаг 4: Вычисление маркеров фона.
Теперь проведем операцию маркирования фона. На изображении Iobrcbr темные пиксели относятся к фону. Таким образом, можно применить операцию пороговой обработки изображения.
Bw=im2bw(Iobrcbr, graythresh(Iobrcbr)); figure, imshow(bw), title("bw")

Пиксели фона являются темными, однако нельзя просто провести морфологические операции над маркерами фона и получить границы объектов, которые мы сегментируем. Мы хотим "утоньшить" фон таким образом, чтобы получить достоверный скелет изображения или, так называемый, передний план полутонового изображения. Это вычисляется с применением подхода по водоразделу и на основе измерения расстояний (до линий водораздела).
D=bwdist(bw); DL=watershed(D); bgm=DL==0; figure, imshow(bgm), title("bgm")

Шаг 5: Вычисление по методу маркерного водораздела на основании модифицированной функции сегментации.
Функция imimposemin может применяться для точного определения локальных минимумов изображения. На основании этого функция imimposemin также может корректировать значения градиентов на изображении и таким образом уточнять расположение маркеров переднего плана и фона.
Gradmag2=imimposemin(gradmag, bgm | fgm4);
И наконец, выполняется операция сегментации на основе водораздела.
L=watershed(gradmag2);
Шаг 6: Визуализация результата обработки.
Отобразим на исходном изображении наложенные маркеры переднего плана, маркеры фона и границы сегментированных объектов.
I4=I; I4(imdilate(L==0, ones(3, 3))|bgm|fgm4)=255; figure, imshow(I4) title("Маркеры и границы объектов, наложенные на исходное изображение")

В результате такого отображения можно визуально анализировать месторасположение маркеров переднего плана и фона.
Представляет интерес также отображение результатов обработки с помощью цветного изображения. Матрица, которая генерируется функциями watershed и bwlabel, может быть конвертирована в truecolor-изображение посредством функции label2rgb.
Lrgb=label2rgb(L, "jet", "w", "shuffle"); figure, imshow(Lrgb) title("Lrgb")

Также можно использовать полупрозрачный режим для наложения псевдоцветовой матрицы меток поверх исходного изображения.
Figure, imshow(I), hold on himage=imshow(Lrgb); set(himage, "AlphaData", 0.3); title("Lrgb, наложенное на исходное изображение в полупрозрачном режиме")