Перенаправление ввода-вывода. Программные каналы и потоки, перенаправление
- Перевод
Если вы уже освоились с основами терминала, возможно, вы уже готовы к тому, чтобы комбинировать изученные команды. Иногда выполнения команд оболочки по одной вполне достаточно для решения некоей задачи, но в некоторых случаях вводить команду за командой слишком утомительно и нерационально. В подобной ситуации нам пригодятся некоторые особые символы, вроде угловых скобок.
Для оболочки, интерпретатора команд Linux, эти дополнительные символы - не пустая трата места на экране. Они - мощные команды, которые могут связывать воедино различные фрагменты информации, разделять то, что было до этого цельным, и делать ещё много всего. Одна из самых простых, и, в то же время, мощных и широко используемых возможностей оболочки - это перенаправление стандартных потоков ввода/вывода.
Три стандартных потока ввода/вывода
Для того, чтобы понять то, о чём мы будем тут говорить, важно знать, откуда берутся данные, которые можно перенаправлять, и куда они идут. В Linux существует три стандартных потока ввода/вывода данных.Первый - это стандартный поток ввода (standard input). В системе это - поток №0 (так как в компьютерах счёт обычно начинается с нуля). Номера потоков ещё называют дескрипторами. Этот поток представляет собой некую информацию, передаваемую в терминал, в частности - инструкции, переданные в оболочку для выполнения. Обычно данные в этот поток попадают в ходе ввода их пользователем с клавиатуры.
Второй поток - это стандартный поток вывода (standard output), ему присвоен номер 1. Это поток данных, которые оболочка выводит после выполнения каких-то действий. Обычно эти данные попадают в то же окно терминала, где была введена команда, вызвавшая их появление.
И, наконец, третий поток - это стандартный поток ошибок (standard error), он имеет дескриптор 2. Этот поток похож на стандартный поток вывода, так как обычно то, что в него попадает, оказывается на экране терминала. Однако, он, по своей сути, отличается от стандартного вывода, как результат, этими потоками, при желании, можно управлять раздельно. Это полезно, например, в следующей ситуации. Есть команда, которая обрабатывает большой объём данных, выполняя сложную и подверженную ошибкам операцию. Нужно, чтобы полезные данные, которые генерирует эта команда, не смешивались с сообщениями об ошибках. Реализуется это благодаря раздельному перенаправлению потоков вывода и ошибок.
Как вы, вероятно, уже догадались, перенаправление ввода/вывода означает работу с вышеописанными потоками и перенаправление данных туда, куда нужно программисту. Делается это с использованием символов > и < в различных комбинациях, применение которых зависит от того, куда, в итоге, должны попасть перенаправляемые данные.
Перенаправление стандартного потока вывода
Предположим, вы хотите создать файл, в который будут записаны текущие дата и время. Дело упрощает то, что имеется команда, удачно названная date , которая возвращает то, что нам нужно. Обычно команды выводят данные в стандартный поток вывода. Для того, чтобы эти данные оказались в файле, нужно добавить символ > после команды, перед именем целевого файла. До и после > надо поставить пробел.При использовании перенаправления любой файл, указанный после > будет перезаписан. Если в файле нет ничего ценного и его содержимое можно потерять, в нашей конструкции допустимо использовать уже существующий файл. Обычно же лучше использовать в подобном случае имя файла, которого пока не существует. Этот файл будет создан после выполнения команды. Назовём его date.txt . Расширение файла после точки обычно особой роли не играет, но расширения помогают поддерживать порядок. Итак, вот наша команда:
$ date > date.txt
Нельзя сказать, что сама по себе эта команда невероятно полезна, однако, основываясь на ней, мы уже можем сделать что-то более интересное. Скажем, вы хотите узнать, как меняются маршруты вашего трафика, идущего через интернет к некоей конечной точке, ежедневно записывая соответствующие данные. В решении этой задачи поможет команда traceroute , которая сообщает подробности о маршруте трафика между нашим компьютером и конечной точкой, задаваемой при вызове команды в виде URL. Данные включают в себя сведения обо всех маршрутизаторах, через которые проходит трафик.
Так как файл с датой у нас уже есть, будет вполне оправдано просто присоединить к этому файлу данные, полученные от traceroute . Для того, чтобы это сделать, надо использовать два символа > , поставленные один за другим. В результате новая команда, перенаправляющая вывод в файл, но не перезаписывающая его, а добавляющая новые данные после старых, будет выглядеть так:
$ traceroute google.com >> date.txt
Теперь нам осталось лишь изменить имя файла на что-нибудь более осмысленное, используя команду mv , которой, в качестве первого аргумента, передаётся исходное имя файла, а в качестве второго - новое:
$ mv date.txt trace1.txt
Перенаправление стандартного потока ввода
Используя знак < вместо > мы можем перенаправить стандартный ввод, заменив его содержимым файла.Предположим, имеется два файла: list1.txt и list2.txt , каждый из которых содержит неотсортированный список строк. В каждом из списков имеются уникальные для него элементы, но некоторые из элементов список совпадают. Мы можем найти строки, которые имеются и в первом, и во втором списках, применив команду comm , но прежде чем её использовать, списки надо отсортировать.
Существует команда sort , которая возвращает отсортированный список в терминал, не сохраняя отсортированные данные в файл, из которого они были взяты. Можно отправить отсортированную версию каждого списка в новый файл, используя команду > , а затем воспользоваться командой comm . Однако, такой подход потребует как минимум двух команд, хотя то же самое можно сделать в одной строке, не создавая при этом ненужных файлов.
Итак, мы можем воспользоваться командой < для перенаправления отсортированной версии каждого файла команде comm . Вот что у нас получилось:
$ comm <(sort list1.txt) <(sort list2.txt)
Круглые скобки тут имеют тот же смысл, что и в математике. Оболочка сначала обрабатывает команды в скобках, а затем всё остальное. В нашем примере сначала производится сортировка строк из файлов, а потом то, что получилось, передаётся команде comm , которая затем выводит результат сравнения списков.
Перенаправление стандартного потока ошибок
И, наконец, поговорим о перенаправлении стандартного потока ошибок. Это может понадобиться, например, для создания лог-файлов с ошибками или объединения в одном файле сообщений об ошибках и возвращённых некоей командой данных.Например, что если надо провести поиск во всей системе сведений о беспроводных интерфейсах, которые доступны пользователям, у которых нет прав суперпользователя? Для того, чтобы это сделать, можно воспользоваться мощной командой find .
Обычно, когда обычный пользователь запускает команду find по всей системе, она выводит в терминал и полезные данные и ошибки. При этом, последних обычно больше, чем первых, что усложняет нахождение в выводе команды того, что нужно. Решить эту проблему довольно просто: достаточно перенаправить стандартный поток ошибок в файл, используя команду 2> (напомним, 2 - это дескриптор стандартного потока ошибок). В результате на экран попадёт только то, что команда отправляет в стандартный вывод:
$ find / -name wireless 2> denied.txt
Как быть, если нужно сохранить результаты работы команды в отдельный файл, не смешивая эти данные со сведениями об ошибках? Так как потоки можно перенаправлять независимо друг от друга, в конец нашей конструкции можно добавить команду перенаправления стандартного потока вывода в файл:
$ find / -name wireless 2> denied.txt > found.txt
Обратите внимание на то, что первая угловая скобка идёт с номером - 2> , а вторая без него. Это так из-за того, что стандартный вывод имеет дескриптор 1, и команда > подразумевает перенаправление стандартного вывода, если номер дескриптора не указан.
И, наконец, если нужно, чтобы всё, что выведет команда, попало в один файл, можно перенаправить оба потока в одно и то же место, воспользовавшись командой &> :
$ find / -name wireless &> results.txt
Итоги
Тут мы разобрали лишь основы механизма перенаправления потоков в интерпретаторе командной строки Linux, однако даже то немногое, что вы сегодня узнали, даёт вам практически неограниченные возможности. И, кстати, как и всё остальное, что касается работы в терминале, освоение перенаправления потоков требует практики. Поэтому рекомендуем вам приступить к собственным экспериментам с > и < .Уважаемые читатели! Знаете ли вы интересные примеры использования перенаправления потоков в Linux, которые помогут новичкам лучше освоиться с этим приёмом работы в терминале?
Встроенные возможности перенаправления в Linux предоставляют вам широкий набор инструментов, используемых упрощения для всех видов задач. Умение управлять различными потоками ввода-вывода в значительно увеличит производительность, как при разработке сложного программного обеспечения, так и при управлении файлами с помощью командной строки.
Потоки ввода-вывода
Ввод и вывод в окружении Linux распределяется между тремя потоками:
- Стандартный ввод (standard input, stdin, поток номер 0)
- Стандартный вывод (standard output, stdout, номер 1)
- Стандартная ошибка, или поток диагностики (standard error, stderr, номер 2)
При взаимодействии пользователя с терминалом стандартный ввод передается через клавиатуру пользователя. Стандартный вывод и стандартная ошибка отображаются на терминале пользователя в виде текста. Все эти три потока называются стандартными потоками.
Стандартный ввод
Стандартный входной поток обычно передаёт данные от пользователя к программе. Программы, которые предполагают стандартный ввод, обычно получают входные данные от устройства (например, клавиатуры). Стандартный ввод прекращается по достижении EOF (end-of-file, конец файла). EOF указывает на то, что больше данных для чтения нет.
Чтобы увидеть, как работает стандартный ввод, запустите программу cat. Название этого инструмента означает «concatenate» (связать или объединить что-либо). Обычно этот инструмент используется для объединения содержимого двух файлов. При запуске без аргументов cat открывает командную строку и принимает содержание стандартного ввода.
Теперь введите несколько цифр:
1
2
3
ctrl-d
Вводя цифру и нажимая enter, вы отправляете стандартный ввод запущенной программе cat, которая принимает эти данные. В свою очередь, программа cat отображает полученный ввод в стандартном выводе.
Пользователь может задать EOF, нажав ctrl-d, после чего программа cat остановится.
Стандартный вывод
Стандартный вывод записывает данные, сгенерированные программой. Если стандартный выходной поток не был перенаправлен, он выведет текст в терминал. Попробуйте запустить следующую команду для примера:
echo Sent to the terminal through standard output
Команда echo без дополнительных опций отображает на экране все аргументы, переданные ей в командной строке.
Теперь запустите echo без аргументов:
Команда вернёт пустую строку.
Стандартная ошибка
Этот стандартный поток записывает ошибки, создаваемые программой, которая вышла из строя. Как и стандартный вывод, этот поток отправляет данные в терминал.
Рассмотрим пример потока ошибок команды ls. Команда ls отображает содержимое каталогов.
Без аргументов эта команда возвращает содержимое текущего каталога. Если указать в качестве аргумента ls имя каталога, команда вернёт его содержимое.
Поскольку каталога % не существует, команда вернёт стандартную ошибку:
ls: cannot access %: No such file or directory
Перенаправление потоков
Linux предоставляет специальные команды для перенаправления каждого потока. Эти команды записывают стандартный вывод в файл. Если вывод перенаправлен в несуществующий файл, команда создаст новый файл с таким именем и сохранит в него перенаправленный вывод.
Команды с одной угловой скобкой переписывают существующий контент целевого файла:
- > — стандартный вывод
- < — стандартный ввод
- 2> — стандартная ошибка
Команды с двойными угловыми скобками не переписывают содержимое целевого файла:
- >> — стандартный вывод
- << — стандартный ввод
- 2>> — стандартная ошибка
Рассмотрим следующий пример:
cat > write_to_me.txt
a
b
c
ctrl-d
В данном примере команда cat используется для записи выходных данных в файл.
Просмотрите содержимое write_to_me.txt:
cat write_to_me.txt
Команда должна вернуть:
Снова перенаправьте cat в файл write_to_me.txt и введите три цифры.
cat > write_to_me.txt
1
2
3
ctrl-d
Теперь проверьте содержимое файла.
cat write_to_me.txt
Команда должна вернуть:
Как видите, файл содержит только последние выходные данные, поскольку в команде, перенаправляющей выход, использовалась одна угловая скобка.
Теперь попробуйте запустить ту же команду с двумя угловыми скобками:
cat >> write_to_me.txt
a
b
c
ctrl-d
Откройте write_to_me.txt:
1
2
3
a
b
c
Команды с двойными угловыми скобками не перезаписывают существующий контент, а дополняют его.
Конвейеры
Конвейеры (pipes) перенаправляют потоки вывода одной команды на вход другой. При этом данные, передаваемые второй программе, не отображаются в терминале. На экране данные появятся только после обработки второй программой.
Конвейеры в Linux представлены вертикальной чертой.
Например:
Такая команда передаст вывод ls (содержимое текущего каталога) программе less, которая отображает передаваемые ей данные построчно. Как правило, ls выводит содержимое каталогов подряд, не разбивая на строки. Если перенаправить вывод ls в less, то последняя команда разделит вывод на строки.
Как видите, конвейер может перенаправить вывод одной команды на вход другой, в отличие от > и >>, которые перенаправляют данные только в файлы.
Фильтры
Фильтры – это команды, которые могут изменить перенаправление и вывод конвейера.
Примечание : Фильтры также являются стандартными командами Linux, которые можно использовать и без конвейера.
- find – выполняет поиск файла по имени.
- grep – выполняет поиск текста по заданному шаблону.
- tee – перенаправляет стандартный ввод в стандартный вывод и один или несколько файлов.
- tr – поиск и замена строк.
- wc – подсчёт символов, строк и слов.
Примеры перенаправления ввода-вывода
Теперь, когда вы ознакомились с основными понятиями и механизмами перенаправления, рассмотрим несколько базовых примеров их использования.
команда > файл
Такой шаблон перенаправляет стандартный вывод команды в файл.
ls ~ > root_dir_contents.txt
Эта команда передает содержимое root каталога системы в качестве стандартного вывода и записывает вывод в файл root_dir_contents. Это удалит все предыдущее содержимое в файле, так как в команде использована одна угловая скобка.
команда > /dev/null
/dev/null – это специальный файл (так называемое «пустое устройство»), который используется для подавления стандартного потока вывода или диагностики, чтобы избежать нежелательного вывода в консоль. Все данные, попадающие в /dev/null, сбрасываются. Перенаправление в /dev/null обычно используется в сценариях оболочки.
ls > /dev/null
Такая команда сбрасывает стандартный выходной поток, возвращаемый командой ls, передав его в /dev/null.
команда 2 > файл
Этот шаблон перенаправляет стандартный поток ошибок команды в файл, перезаписывая его текущее содержимое.
mkdir "" 2> mkdir_log.txt
Эта команда перенаправит ошибку, вызванную неверным именем каталога, и запишет её в log.txt. Обратите внимание: ошибка по-прежнему отображается в терминале.
команда >> файл
Этот шаблон перенаправляет стандартный выход команды в файл, не переписывая текущего содержимого файла.
echo Written to a new file > data.txt
echo Appended to an existing file"s contents >> data.txt
Эта пара команд сначала перенаправляет вводимый пользователем текст в новый файл, а затем вставляет его в существующий файл, не переписывая его содержимого.
команда 2>>файл
Этот шаблон перенаправляет стандартный поток ошибок команды в файл, не перезаписывая существующего содержимого файла. Он подходит для создания логов ошибок программы или сервиса, поскольку содержимое лога не будет постоянно обновляться.
find "" 2> stderr_log.txt
wc "" 2>> stderr_log.txt
Приведенная выше команда перенаправляет сообщение об ошибке, вызванное неверным аргументом find, в файл stderr_log.txt, а затем добавляет в него сообщение об ошибке, вызванной недействительным аргументом wc.
команда | команда
Этот шаблон перенаправляет стандартный выход первой команды на стандартный вход второй команды.
find /var lib | grep deb
Эта команда ищет в каталоге /var и его подкаталогах имена файлов и расширения deb и возвращает пути к файлам, выделяя шаблон поиска красным цветом.
команда | tee файл
Такой шаблон перенаправляет стандартный вывод команды в файл и переписывает его содержимое, а затем отображает перенаправленный выход в терминале. Если указанного файла не существует, он создает новый файл.
В данном шаблоне команда tee, как правило, используется для просмотра вывода программы и одновременного сохранения его в файл.
wc /etc/magic | tee magic_count.txt
Такая команда передаёт количество символов, строк и слов в файле magic (Linux использует его для определения типов файлов) команде tee, которая отправляет эти данные в терминал и в файл magic_count.txt.
команда | команда | команда >> файл
Этот шаблон перенаправляет стандартный вывод первой команды и фильтрует ее через следующие две команды, а затем добавляет окончательный результат в файл.
ls ~ | grep *tar | tr e E >> ls_log.txt
Такая команда отправляет вывод ls для каталога root команде grep. В свою очередь, grep ищет в полученных данных файлы tar. После этого результат grep передаётся команде tr, которая заменит все символы е символом Е. Полученный результат будет добавлен в файл ls_log.txt (если такого файла не существует, команда создаст его автоматически).
Заключение
Функции перенаправления ввода-вывода в Linux сначала кажутся слишком сложными. Однако работа с перенаправлением – один из важнейших навыков системного администратора.
Чтобы узнать больше о какой-либо команде, используйте:
man command | less
Например:
Такая команда вернёт полный список команд для tee.
Tags:Если вывод в (графическую) консоль не очень объёмный, можно просто выдельть мышкой кусок и вставить его в сообщение щелчком средней кнопки. В противном случае можно использовать перенаправление вывода в файл через "воронку", например так:
Some_command parameters > logfile.txt
Чтобы видеть результат выполнения на экране, и одновременно писать в файл, можно воспользоваться командой tee :
Some_command parameters | tee -a logfile.txt
Команда setterm -dump создает "слепок" буфера текущей виртуальной консоли в виде простого текстового файла с именем по умолчанию - screen.dump. В качестве ее аргумента можно использовать номер консоли, для которой требуется сделать дамп. А добавление опции -file имя_файла перенаправит этот дамп в файл с указанным именем. Опция же -append присоединит новый дамп к уже существующему файлу - "умолчальному" screen.dump или поименованному опцией -file .
Т.е. после использования команды, например
Setterm -dump -file /root/screenlog
соответственно в файле /root/screenlog будет содержимое одной страницы консоли.
Нашёл еще одно решение для копирования/вставки текста в текстовой консоли без мыши. Также можно копировать текст из буфера прокрутки (т.е. всё что на экране и выше за экраном). Чтобы лучше разобраться, читайте о консольном менеджере окон screen . Также может пригодиться увеличить размер буфера прокрутки.
1) Запускаем screen
2) Нажимаем Enter. Всё. Мы находимся в нулевом окне консоли.
3) Выполняем нужные команды, вывод которых необходимо скопировать.
4) Ctrl+A, Ctrl+[ - мы в режиме копирования. Ставим курсор на начало выделения, жмём пробел, потом ставим курсор на конец выделения, жмём пробел. Текст скопирован в буфер.
5) Ctrl+A, с - мы создали новое 1-е окно.
6) Ctrl+A, 1 - мы перешли на 1-е окно.
7) Открываем любой (?) текстовый редактор (я пробовал в mc), и жмём Ctrl+A, Ctrl+] - текст вставлен. Сохраняем.
8) Ctrl+A, Ctrl+0 - вернуться обратно в нулевое окно.
Как увеличить буфер обратной прокрутки?
Первым решением будет увеличить дефолтный (умолчальный) размер буфера в исходниках ядра и перекомпилировать его. Позвольте предположить, что вы столь же не склонны заниматься этим, как и я, и поискать средство более гибкое.
И такое средство есть, а называется оно framebuffer console , для краткости fbcon . Это устройство имеет файл документации fbcon.txt ; если вы устанавливали документацию к ядру, то он у вас есть. Выискивайте его где-то в районе /usr/share ветви (я не могу указать точный путь из-за разницы в дистрибутивах).
На этом месте прошу прощения: мы должны сделать небольшое отступление и немного поговорить о видеобуфере (framebuffer ).
Видеобуфер - это буфер между дисплеем и видеоадаптером. Его прелесть в том, что им можно манипулировать: он позволяет трюки, которые не прошли бы, будь адаптер связан напрямую с дисплеем.
Один из таких трюков связан с буфером прокрутки; оказывается, вы можете "попросить" видеобуфер выделить больше памяти буферу прокрутки. Достигается это через загрузочные параметры ядра. Сначала вы требуете framebuffer (видеобуфер); Затем запрашиваете больший буфер прокрутки.
Нижеследующий пример касается GRUB , но может быть легко адаптирован к LILO . В файле настройки GRUB - menu.lst - найдите соответствующую ядру строчку, и затем: Удалите опцию vga=xxx , если таковая присутствует. Добавьте опцию video=vesabf или то, что соответствует вашему "железу". Добавьте опцию fbcon=scrollback:128 . После этой процедуры, строка параметров ядра должна выглядеть приблизительно так:
Kernel /vmlinuz root=/dev/sdb5 video=radeonfb fbcon=scrollback:128
Спрашивается, зачем удалять опцию vga=xxx ? Из-за возможных конфликтов с видео-опцией. На своем ATI адаптере, я не могу изменить буфер прокрутки, если vga=xxx присутствует в списке. Возможно в вашем случае это не так. Если вышеперечисленные опции работают - хорошо; но что, если вы хотите увеличить число строк, или установить более мелкий шрифт на экране? Вы всегда делали это при помощи опции vga=xxx - а она-то и исчезла. Не переживайте - то же самое может быть достигнуто изменением параметров fbcon, как описано в файле fbcon.txt (но не описано в данной статье).
С опцией fbcon=scrollback:128 у меня буфер прокрутки увеличился до 17 экранов (35 раз Shift+PgUp по полэкрана). Кстати, 128 - это килобайт. Автор статьи утверждает, что больше установить нельзя. Я и не пробовал.
Можно заюзать script .
Script filename.log
когда все нужные команды выполнены -
Все записано в filename.log
В FreeBSD есть замечательная утилита watch, которая позволяет мониторить терминалы, но как оказалось, в Linux она выполняет совсем иные функции =\ Стоит погуглить на эту тему, чего-нть да найдется...
Операторы перенаправления команд используются для изменения местоположений потоков ввода и вывода команд, заданных по умолчанию, на какие-либо другие. Местоположение потоков ввода и вывода называется дескриптор.
В следующей таблице описаны операторы перенаправления потоков ввода и вывода команд.
| Оператор перенаправления | Описание |
|---|---|
| > | Записывает данные на выходе команды вместо командной строки в файл или на устройство, например, на принтер. |
| < | Читает поток входных данных команды из файла, а не с клавиатуры. |
| >> | Добавляет выходные данные команды в конец файла, не удаляя при этом существующей информации из файла. |
| >& | Считывает данные на выходе одного дескриптора как входные данные для другого дескриптора. |
| <& | Считывает входные данные одного дескриптора как выходные данные другого дескриптора. |
| | | Считывает выходные данные одной команды и записывает их на вход другой команды. Эта процедура известна под названием «канал». |
По умолчанию, входные данные команды (дескриптор STDIN) отсылаются с клавиатуры интерпретатору команд Cmd.exe, далее Cmd.exe отправляет выходные данные команды (дескриптор STDOUT) в окно командной строки.
В следующей таблице представлены доступные дескрипторы.
Номера от 0 до 9 представляют первые 10 дескрипторов. Для запуска программы и перенаправления любого из 10 дескрипторов используется интерпретатор команд Cmd.exe. Для задания требуемого дескриптора перед оператором перенаправления введите его номер. Если дескриптор не определен, то по умолчанию оператором перенаправления ввода «<» будет ноль (0), а оператором перенаправления вывода «>» будет единица (1). После ввода оператора «<» или «>» необходимо указать, откуда читать и куда записывать данные. Можно задать имя файла или любой из существующих дескрипторов.
Для задания перенаправления в существующие дескрипторы используется амперсанд (&), затем номер требуемого дескриптора (например, & номер_дескриптора ). Например, для перенаправления дескриптора 2 (STDERR) в дескриптор 1 (STDOUT) введите:
Дублирование дескрипторов
Оператор перенаправления «&» дублирует выходные или входные данные с одного заданного дескриптора на другой заданный дескриптор. Например, для отправки выводных данных команды dir в файл File.txt и отправки ошибки вывода в файл File.txt введите:
dir>c:\file.txt 2>&1
При дублировании дескриптора происходит копирование всех его исходных характеристик. Например, если дескриптор доступен только для записи, то все его дубликаты будут доступны только для записи. Нельзя продублировать дескриптор с доступом только для чтения в дескриптор с доступом только для записи.
Перенаправление ввода команд (<)
Для перенаправления ввода команд с цифровой клавиатуры на файл или на устройство используйте оператор «<». Например, для ввода команды sort из файла List.txt введите:
sort Содержимое файла File.txt появится в командной строке в виде списка в алфавитном порядке. Оператор «<» открывает заданное имя файла с доступом только для чтения. Поэтому с его
помощью нельзя записывать в файл. Например, при запуске программы с оператором <&2 все
попытки прочитать дескриптор 0 ни к чему не приведут, так как изначально он был открыт с
доступом только для записи. Примечание Выходные данные практически всех команд высвечиваются в окне командной строки. Даже команды,
выводящие данные на диск или принтер, выдают сообщения и запросы в окне командной строки. Для перенаправления вывода команд из окна командной строки в файл или на устройство
применяется оператор «>». Этот оператор используется с большинством команд. Например, для
перенаправления вывода команды dir в файл Dirlist.txt введите: dir>dirlist.txt Если файл Dirlist.txt не существует, интерпретатор команд Cmd.exe создаст его. Если файл
существует, Cmd.exe заменит информацию в файле на данные, полученные от команды dir
. Для запуска команды netsh routing dump
и последующей отправки результатов ее работы в
Route.cfg введите: netsh routing dump > c:\route.cfg Оператор «>» открывает заданный файл с доступом только для записи. Поэтому с помощью
данного оператора файл прочитать нельзя. Например, при запуске программы с оператором
перенаправления <&0 все попытки записать дескриптор 1 ни к чему не приведут, так как
изначально дескриптор 0 был открыт с доступом только для чтения. Примечание. Для использования оператора перенаправления ввода необходимо, чтобы задаваемый файл уже
существовал. Если файл для ввода существует, то интерпретатор команд Cmd.exe открывает его с
доступом только для чтения и его содержимое отправляет в команду так, как если бы это был
ввод с цифровой клавиатуры. При задании дескриптора интерпретатор команд Cmd.exe дублирует
его в дескриптор, существующий в системе. Например, для считывания файла File.txt на вход в дескриптор 0 (STDIN) введите: Для открытия файла File.txt, сортировки его содержимого и последующей отправки в окно
командной строки (STDOUT) введите: sort< file.txt Для того чтобы найти файл File.txt и перенаправить дескриптор 1 (STDOUT) и дескриптор 2
(STDERR) в Search.txt введите: findfile file.txt>search.txt 2<&1 Для дублирования определенного пользователем дескриптора 3 в качестве входной информации для
дескриптора 0 (STDIN) введите: При перенаправлении вывода в файл и задании существующего имени файла интерпретатор команд
Cmd.exe открывает файл с доступом только для записи и переписывает его содержимое. Если
дескриптор задан, интерпретатор команд Cmd.exe дублирует файл в существующий дескриптор. Для дублирования определенного пользователем дескриптора 3 в дескриптор 1 введите: Для перенаправления всех выходных данных, включая выходные данные дескриптора 2 (STDERR),
команды ipconfig
в дескриптор 1 (STDOUT) и последующего перенаправления выходных
данных в Output.log введите: ipconfig.exe>>output.log 2>&1 Для добавления выходных данных команды в конец файла без потери хранящейся в нем информации
используется двойной символ «больше» (>>). Например, следующая команда добавляет список
каталогов, созданный командой dir
, в файл Dirlist.txt: dir>>dirlist.txt Для добавления выходных данных команды netstat
в конец файла Tcpinfo.txt введите: netstat>>tcpinfo.txt Иногда удобнее записывать это следующим образом:
SET OutFile="%~n0.html"
> %OutFile% ECHO ^ Оператор канала «вертикальная линия» (|) забирает выходные данные одной команды (по умолчанию
STDOUT) и направляет их на вход другой команды (по умолчанию STDIN). Например, следующая
команда сортирует каталог: В данном примере обе команды запускаются одновременно, но команда sort
приостанавливает работу до получения выходных данных команды dir
. Команда sort
использует выходные данные команды dir
в качестве своих входных данных, а затем свои
выходные данные отправляет в дескриптор 1 (STDOUT). Комбинируя команды-фильтры с другими командами и именами файлов, можно создавать команды на
заказ. Например, для сохранения имен файлов, содержащих строку «LOG», используется следующая
команда: dir /b | find "LOG" > loglist.txt Выход команды dir
отсылается в команду-фильтр find
. Имена файлов, содержащие
строку «LOG», хранятся в файле Loglist.txt в виде списка (например, NetshConfig.log,
Logdat.svd и Mylog.bat). При использовании более одного фильтра в одной команде их необходимо отделять с помощью
канала (|). Например, следующая команда ищет в каждом каталоге диска C файлы, в названии
которых присутствует строка «Log», и выводит их постранично на экран: dir c:\ /s /b | find "LOG" | more Наличие канала (|) указывает cmd.exe ,
что выход команды DIR нужно отправить
команде-фильтру find
. Команда find
выбирает только те имена файлов, в которых
содержится строка «LOG». Команда more
выводит на экран имена файлов, полученные
командой find
с паузой после заполнения каждого экрана. Дополнительные сведения о
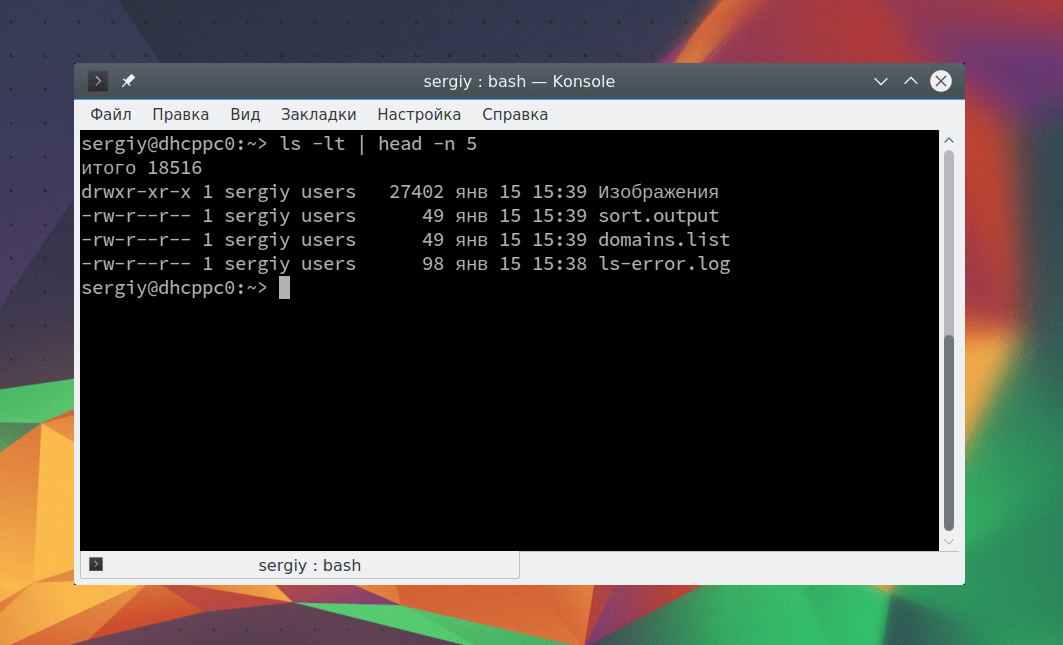
командах-фильтрах смотри в разделе Одна из самых интересных и полезных тем для системных администраторов и новых пользователей, которые только начинают разбираться в работе с терминалом - это перенаправление потоков ввода вывода Linux. Эта особенность терминала позволяет перенаправлять вывод команд в файл, или содержимое файла на ввод команды, объединять команды вместе, и образовать конвейеры команд. В этой статье мы рассмотрим как выполняется перенаправление потоков ввода вывода в Linux, какие операторы для этого используются, а также где все это можно применять. Все команды, которые мы выполняем, возвращают нам три вида данных: В Linux все субстанции считаются файлами, в том числе и потоки ввода вывода linux - файлы. В каждом дистрибутиве есть три основных файла потоков, которые могут использовать программы, они определяются оболочкой и идентифицируются по номеру дескриптора файла: Перенаправление ввода / вывода позволяет заменить один из этих файлов на свой. Например, вы можете заставить программу читать данные из файла в файловой системе, а не клавиатуры, также можете выводить ошибки в файл, а не на экран и т д. Все это делается с помощью символов "<"
и ">"
. Все очень просто. Вы можете перенаправить вывод в файл с помощью символа >. Например, сохраним вывод команды top: top -bn 5 > top.log Опция -b заставляет программу работать в не интерактивном пакетном режиме, а n - повторяет операцию пять раз, чтобы получить информацию обо всех процессах. Теперь смотрим что получилось с помощью cat: Символ ">"
перезаписывает информацию из файла, если там уже что-то есть. Для добавления данных в конец используйте ">>"
. Например, перенаправить вывод в файл linux еще для top: top -bn 5 >> top.log По умолчанию для перенаправления используется дескриптор файла стандартного вывода. Но вы можете указать это явно. Эта команда даст тот же результат: top -bn 5 1>top.log Чтобы перенаправить вывод ошибок в файл вам нужно явно указать дескриптор файла, который собираетесь перенаправлять. Для ошибок - это номер 2. Например, при попытке получения доступа к каталогу суперпользователя ls выдаст ошибку: Вы можете перенаправить стандартный поток ошибок в файл так: ls -l /root/ 2> ls-error.log Чтобы добавить данные в конец файла используйте тот же символ: ls -l /root/ 2>>ls-error.log Вы также можете перенаправить весь вывод, ошибки и стандартный поток вывода в один файл. Для этого есть два способа. Первый из них, более старый, состоит в том, чтобы передать оба дескриптора: ls -l /root/ >ls-error.log 2>&1 Сначала будет отправлен вывод команды ls в файл ls-error.log c помощью первого символа перенаправления. Дальше в тот же самый файл будут направлены все ошибки. Второй метод проще: ls -l /root/ &> ls-error.log Также можно использовать добавление вместо перезаписи: ls -l /root/ &>> ls-error.log Большинство программ, кроме сервисов, получают данные для своей работы через стандартный ввод. По умолчанию стандартный ввод ожидает данных от клавиатуры. Но вы можете заставить программу читать данные из файла с помощью оператора "<"
: cat Вы также можете сразу же перенаправить вывод тоже в файл. Например, пересортируем список: sort Таким образом, мы в одной команде перенаправляем ввод вывод linux. Можно работать не только с файлами, но и перенаправлять вывод одной команды в качестве ввода другой. Это очень полезно для выполнения сложных операций. Например, выведем пять недавно измененных файлов: ls -lt | head -n 5 С помощью утилиты xargs вы можете комбинировать команды таким образом, чтобы стандартный ввод передавался в параметры. Например, скопируем один файл в несколько папок: echo test/ tmp/ | xargs -n 1 cp -v testfile.sh Здесь параметр -n 1 задает, что для одной команды нужно подставлять только один параметр, а опция -v в cp позволяет выводить подробную информацию о перемещениях. Еще одна, полезная в таких случаях команда - это tee. Она читает данные из стандартного ввода и записывает в стандартный вывод или файлы. Например: echo "Тест работы tee" | tee file1 В сочетании с другими командами все это может использоваться для создания сложных инструкций из нескольких команд. В этой статье мы рассмотрели основы перенаправления потоков ввода вывода Linux. Теперь вы знаете как перенаправить вывод в файл linux или вывод из файла. Это очень просто и удобно. Если у вас остались вопросы, спрашивайте в комментариях!Перенаправление вывода команд (>)
Использование оператора «<&» для перенаправления ввода и дублирования
Использование оператора «>&» для перенаправления ввода и дублирования
Использование оператора «>>» для добавления вывода
Использование оператора канала (|)
Комбинирование команд с операторами перенаправления
Перенаправить вывод в файл

Перенаправить ошибки в файл

$ cat ls-error.log

Перенаправить стандартный вывод и ошибки в файл

Стандартный ввод из файла


Использование тоннелей


Выводы